Function secret sharing (FSS) primitives including:
- 2-party distributed point function (DPF), based on Boyle et al. (CCS '16) or Half-Tree (EUROCRYPT '23).
- 2-party distributed comparison function (DCF), based on Boyle et al. (EUROCRYPT '21) or Grotto (CCS '23).
- 2-party verifiable distributed point function (VDPF), based on Castro & Polychroniadou (EUROCRYPT '22).
Features:
- First-class support for GPU (based on CUDA)
- Top-tier performance shown by benchmarks
- Well-commented and documented
- Header-only library, easy for integration
Multi-party computation (MPC) is a subfield of cryptography that aims to enable a group of parties (e.g., servers) to jointly compute a function over their inputs while keeping the inputs private.
Secret sharing is a method that distributes a secret among a group of parties, such that no individual party holds any information about the secret.
For example, a number
FSS is a scheme to secret-share a function into a group of function shares.
Each function share, called as a key, can be individually evaluated on a party.
The outputs of the keys are the shares of the original function output.
FSS consists of 2 methods: Gen for generating function shares as keys and Eval for evaluating a key to get an output share.
FSS's workflow is shown below:
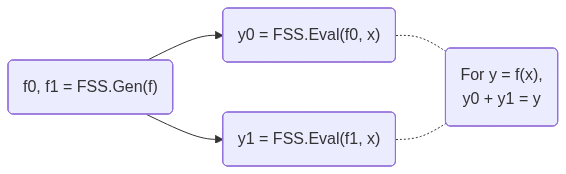
DPF/DCF are FSS for point/comparison functions.
They are called out because 2-party DPF/DCF can have
- CMake >= 3.22
- CUDA toolkit >= 12.0 (for C++20 support). Tested on the latest CUDA toolkit.
- OpenSSL 3 (only required for CPU with AES-128 MMO PRG)
Clone the repository:
git clone https://github.com/myl7/fss.git
cd fssOption A: Install via CMake and use find_package
cmake -B build -DBUILD_TESTING=OFF -DCMAKE_INSTALL_PREFIX=/path/to/install
cmake --build build
cmake --install buildThen in your project's CMakeLists.txt:
find_package(fss REQUIRED)
target_link_libraries(your_target fss::fss)When configuring your project, point CMake to the install prefix:
cmake -B build -DCMAKE_PREFIX_PATH=/path/to/installOption B: Use as a subdirectory (header-only)
Without installing, you can define the target directly in your CMakeLists.txt, like the samples do:
add_library(fss INTERFACE)
target_include_directories(fss INTERFACE "/path/to/fss/include")
target_compile_features(fss INTERFACE cxx_std_20 cuda_std_20)Then link it in your project:
target_link_libraries(your_target fss)This walks through using DPF and DCF on the CPU with AES-128 MMO PRG. This PRG requires OpenSSL.
-
Include the headers and set up type aliases:
#include <fss/dpf.cuh> #include <fss/dcf.cuh> #include <fss/group/bytes.cuh> #include <fss/prg/aes128_mmo.cuh> constexpr int kInBits = 8; // Input domain: 2^8 = 256 values using In = uint8_t; using Group = fss::group::Bytes; // DPF uses mul=2, DCF uses mul=4 using DpfPrg = fss::prg::Aes128Mmo<2>; using DcfPrg = fss::prg::Aes128Mmo<4>; using Dpf = fss::Dpf<kInBits, Group, DpfPrg, In>; using Dcf = fss::Dcf<kInBits, Group, DcfPrg, In>;
-
Create the PRG with AES keys and instantiate DPF/DCF:
// DPF PRG needs 2 AES keys unsigned char key0[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}; unsigned char key1[16] = {16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1}; const unsigned char *keys[2] = {key0, key1}; auto ctxs = DpfPrg::CreateCtxs(keys); DpfPrg prg(ctxs); Dpf dpf{prg};
-
Run
Gento generate correction words (keys) from secret inputs:In alpha = 42; // Secret point / threshold int4 beta = {7, 0, 0, 0}; // Secret payload (LSB of .w must be 0) // Random seeds for the two parties (LSB of .w must be 0) int4 seeds[2] = { {0x11111111, 0x22222222, 0x33333333, 0x44444440}, {0x55555555, 0x66666666, 0x77777777, static_cast<int>(0x88888880u)}, }; Dpf::Cw cws[kInBits + 1]; dpf.Gen(cws, seeds, alpha, beta);
-
Run
Evalon each party and reconstruct using the group:// Each party evaluates independently int4 y0 = dpf.Eval(false, seeds[0], cws, alpha); int4 y1 = dpf.Eval(true, seeds[1], cws, alpha); // Reconstruct via the group: convert to group elements, add, convert back // For Bytes group this is XOR; for Uint group this is arithmetic addition int4 sum = (Group::From(y0) + Group::From(y1)).Into(); // sum == beta at x == alpha, 0 otherwise
-
Free the AES contexts when done:
DpfPrg::FreeCtxs(ctxs);
DCF follows the same pattern — use DcfPrg (mul=4, needs 4 AES keys), Dcf, and Dcf::Cw. The reconstructed output equals beta when x < alpha and 0 otherwise.
Link with OpenSSL in your CMakeLists.txt:
find_package(OpenSSL REQUIRED)
target_link_libraries(your_target fss OpenSSL::Crypto)See samples/dpf_dcf_cpu.cu for the complete working example.
This walks through using DPF and DCF on the GPU with ChaCha PRG.
-
Include the headers and set up type aliases:
#include <fss/dpf.cuh> #include <fss/dcf.cuh> #include <fss/group/bytes.cuh> #include <fss/prg/chacha.cuh> constexpr int kInBits = 8; using In = uint8_t; using Group = fss::group::Bytes; // DPF uses mul=2, DCF uses mul=4 using DpfPrg = fss::prg::ChaCha<2>; using DcfPrg = fss::prg::ChaCha<4>; using Dpf = fss::Dpf<kInBits, Group, DpfPrg, In>; using Dcf = fss::Dcf<kInBits, Group, DcfPrg, In>;
-
Set up a nonce in constant memory and create the PRG in a kernel:
__constant__ int kNonce[2] = {0x12345678, 0x9abcdef0}; __global__ void GenKernel(Dpf::Cw *cws, const int4 *seeds, const In *alphas, const int4 *betas) { int tid = blockIdx.x * blockDim.x + threadIdx.x; DpfPrg prg(kNonce); Dpf dpf{prg}; int4 s[2] = {seeds[tid * 2], seeds[tid * 2 + 1]}; dpf.Gen(cws + tid * (kInBits + 1), s, alphas[tid], betas[tid]); }
-
Prepare host data, copy to device, and launch the
Genkernel:int4 *d_seeds = /* cudaMalloc + cudaMemcpy seeds to device */; In *d_alphas = /* cudaMalloc + cudaMemcpy alphas to device */; int4 *d_betas = /* cudaMalloc + cudaMemcpy betas to device */; Dpf::Cw *d_cws; cudaMalloc(&d_cws, sizeof(Dpf::Cw) * (kInBits + 1) * N); GenKernel<<<blocks, threads>>>(d_cws, d_seeds, d_alphas, d_betas);
-
Write and launch an
Evalkernel for each party, then copy results back:__global__ void EvalKernel(int4 *ys, bool party, const int4 *seeds, const Dpf::Cw *cws, const In *xs) { int tid = blockIdx.x * blockDim.x + threadIdx.x; DpfPrg prg(kNonce); Dpf dpf{prg}; ys[tid] = dpf.Eval(party, seeds[tid], cws + tid * (kInBits + 1), xs[tid]); } // Launch for party 0 and party 1, then copy d_ys back to host EvalKernel<<<blocks, threads>>>(d_ys, false, d_seeds0, d_cws, d_xs); EvalKernel<<<blocks, threads>>>(d_ys, true, d_seeds1, d_cws, d_xs);
-
Reconstruct on the host using the group, same as the CPU case:
int4 sum = (Group::From(h_y0s[i]) + Group::From(h_y1s[i])).Into();
DCF follows the same pattern — use DcfPrg (mul=4), Dcf, and Dcf::Cw.
See samples/dpf_dcf_gpu.cu for the complete working example.
You may see warnings like "integer constant is so large that it is unsigned" during compilation. These cannot be easily suppressed but are harmless and can be safely ignored.
Microbenchmarks for DPF/DCF Gen/Eval using Google Benchmark, covering both CPU (AES-128 MMO PRG) and GPU (ChaCha PRG) paths.
Configure with BUILD_BENCH=ON and build the targets:
cmake -B build -DBUILD_BENCH=ON -DCMAKE_BUILD_TYPE=RelWithDebInfo
cmake --build build --target bench_cpu bench_gpuRun all benchmarks:
./build/bench_cpu
./build/bench_gpuRun a subset using --benchmark_filter (regex):
./build/bench_cpu --benchmark_filter=BM_DcfGen
./build/bench_cpu --benchmark_filter=BM_DpfEval_Uint/20Run on Intel Xeon Platinum 8352V @ 2.10GHz (Ice Lake), single core, performance governor, pinned with taskset -c 0.
-------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------
BM_DpfEval_Uint_Aes/20 1704 ns 1703 ns 423203
BM_DpfEval_Uint_Aes/14 1117 ns 1117 ns 623553
BM_DpfEval_Uint_Aes/17 1408 ns 1407 ns 501122
BM_DpfGen_Uint_Aes/20 3226 ns 3224 ns 215461
BM_DpfEval_Bytes_Aes/20 1609 ns 1609 ns 431192
BM_DpfEvalAll_Uint_Aes/20 166795841 ns 166741828 ns 5 items_per_second=6.28862M/s
BM_DpfEval_Uint_ChaCha/20 44940 ns 44911 ns 16889
BM_DpfEval_Uint_AesSoft/20 16184 ns 16172 ns 42681
BM_DcfEval_Uint_Aes/20 4318 ns 4315 ns 193683
BM_DcfGen_Uint_Aes/20 7461 ns 7456 ns 94162
BM_DcfEval_Bytes_Aes/20 3685 ns 3683 ns 187611
BM_DcfEvalAll_Uint_Aes/20 267235391 ns 267066584 ns 3 items_per_second=3.92627M/s
BM_DcfEvalAll_Bytes_Aes/20 276631759 ns 276403133 ns 2 items_per_second=3.79365M/s
BM_VdpfEval_Uint_Aes_Sha256/20 2959 ns 2957 ns 238919
BM_VdpfGen_Uint_Aes_Sha256/20 6000 ns 5998 ns 100000
BM_VdpfEval_Uint_Aes_Blake3/20 7354 ns 7349 ns 95737
BM_VdpfProve_Uint_ChaCha_Blake3/20 1890 ns 1888 ns 363291
BM_VdpfEvalAll_Uint_Aes_Sha256/20 1424750352 ns 1424019165 ns 1 items_per_second=736.35k/s
BM_HalfTreeDpfEval_Uint_Aes/20 985 ns 985 ns 722157
BM_HalfTreeDpfGen_Uint_Aes/20 2204 ns 2203 ns 319493
BM_HalfTreeDpfEvalAll_Uint_Aes/20 97681794 ns 97599273 ns 7 items_per_second=10.7437M/s
BM_GrottoDcfEval_Aes/20 46.9 ns 46.9 ns 15044877
BM_GrottoDcfPreprocess_Aes/20 130893070 ns 130785021 ns 5
BM_GrottoDcfPreprocessEvalAll_Aes/20 260231883 ns 260023892 ns 3 items_per_second=4.03261M/s
Run on NVIDIA RTX A6000 (48GB VRAM), CUDA 12.6, driver 560.35.05. Each iteration runs 1M (2^20) Gen/Eval in parallel. The GPU was warmed up before running the benchmarks.
-------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------------
BM_DpfEval_Uint/20/manual_time 5003011 ns 7320763 ns 100 items_per_second=209.589M/s
BM_DpfEval_Uint/14/manual_time 1283038 ns 3108089 ns 527 items_per_second=817.26M/s
BM_DpfEval_Uint/17/manual_time 1664344 ns 3599944 ns 425 items_per_second=630.024M/s
BM_DpfGen_Uint/20/manual_time 5530518 ns 7397631 ns 113 items_per_second=189.598M/s
BM_DpfEval_Bytes/20/manual_time 4356800 ns 6046874 ns 139 items_per_second=240.676M/s
BM_DpfEval_Uint_AesSoft/20/manual_time 20864855 ns 22624837 ns 29 items_per_second=50.2556M/s
BM_DcfEval_Uint/20/manual_time 4356972 ns 6142652 ns 173 items_per_second=240.666M/s
BM_DcfGen_Uint/20/manual_time 5926477 ns 8139248 ns 114 items_per_second=176.931M/s
BM_VdpfEval_Uint/20/manual_time 3990959 ns 5761747 ns 155 items_per_second=262.738M/s
BM_VdpfGen_Uint/20/manual_time 5787254 ns 7720680 ns 130 items_per_second=181.187M/s
BM_HalfTreeDpfEval_Uint/20/manual_time 1746974 ns 4011309 ns 403 items_per_second=600.224M/s
BM_HalfTreeDpfGen_Uint/20/manual_time 5996544 ns 8311199 ns 118 items_per_second=174.863M/s
GPU kernel register usage (compiled for sm_52, --ptxas-options=-v):
| Kernel | Group | Registers | Stack | Smem |
|---|---|---|---|---|
| DpfEval | Uint/Bytes | 39 | ||
| DpfGen | Uint/Bytes | 48 | ||
| DpfEvalAes | Uint | 72 | 992B | 1280B |
| DpfGenAes | Uint | 72 | 992B | 1280B |
| HalfTreeDpfEval | Uint | 41 | ||
| HalfTreeDpfGen | Uint | 47 | ||
| VdpfEval | Uint | 38 | ||
| VdpfGen | Uint | 72 | ||
| DcfEval | Uint | 38 | ||
| DcfGen | Uint | 56 |
The AES-based kernels use shared memory and spill to stack. All other kernels have zero spills.
Generate a CPU flamegraph with perf and FlameGraph:
perf record -g ./build/bench_cpu --benchmark_filter=BM_DpfEval_Uint/20
perf script | /path/to/FlameGraph/stackcollapse-perf.pl | /path/to/FlameGraph/flamegraph.pl > build/flamegraph.svgOpen build/flamegraph.svg in a browser. The graph is interactive: click a frame to zoom in.
Apache License, Version 2.0
Copyright (C) 2026 Yulong Ming [email protected]