Domain yang dipilih pada proyek ini adalah keuangan, ekonomi dan bisnis. Proyek ini sendiri mengusung judul Google Play Store Recommendation System
Google play store adalah tempat untuk mengunduh aplikasi-aplikasi berbasis android. Pertumbuhan signifikan pasar aplikasi seluler berdampak besar pada teknologi digital dengan jumlah aplikasi yang tersedia di Google Play Store hingga Maret 2021 sekitar 2,8 juta dan akan terus bertambah seiring waktu (Appbrain, 2021). Jutaan aplikasi yang tersedia di Google Play Store tentunya memiliki kategori yang bermacam-macam seperti kategori social, shopping, hingga game. Para pengguna di Google Play Store tentu akan sangat kebingungan untuk memilik aplikasi yang mereka butuhkan dari jutaan aplikasi yang tersedia dengan berbagai macam kategori.
Menjawab pertanyaan di atas, maka Google Play Store perlu menambahkan sistem rekomendasi yang bertugas memberikan rekomendasi kepada para pengguna sehingga mereka tidak kebingungan mencari aplikasi yang mungkin mereka butuhkan. Salah satu metode untuk memberikan rekomendasi adalah metode Content Based Filtering. Metode ini merupakan metode yang merekomendasikan item yang mirip dengan item sebelumnya yang disukai atau dipilih oleh pengguna. Kemiripan item ini dapat dinilai dari beberapa hal seperti kemiripan kategori, tipe, jenis, dan lain sebagainya.
Berdasarkan dari uraian-uraian di atas maka penulis memiliki sebuah ide guna membantu para user di Google Play Store untuk mendapatkan rekomendasi aplikasi yang mungkin mereka butuhkan. Oleh karena itu, penulis menyusun sebuah proyek dengan judul Google Play Store Recommendation System. Dengan adanya proyek ini, penulis berharap para user Google Play Store akan sangat terbantu.
Berdasarkan pada latar belakang di atas, permasalahan yang dapat diselesaikan pada proyek ini adalah sebagai berikut :
- Bagaimana cara melakukan analisis dan pemrosesan data agar dapat digunakan pada model sistem rekomendasi?
- Bagaimana cara memberikan rekomendasi aplikasi yang mungkin dibutuhkan dan disukai oleh pengguna?
Tujuan atau goals proyek ini dibuat adalah sebagai berikut :
- Mendapatkan data yang sudah dianalisis dan diproses sehingga dapat digunakan pada model sistem rekomendasi.
- Mendapatkan rekomendasi aplikasi yang mungkin dibutuhkan dan disukai oleh pengguna.
Solusi yang dapat dilakukan agar goals terpenuhi adalah sebagai berikut :
-
Melakukan exploratory data analysis yang didalamnya terdapat analisa, eksplorasi, processing data dengan memvisualisasikan data agar memperjelas gambaran mengenai karakteristik data tersebut. Berikut adalah analisa yang dapat dilakukan :
- Menganalisis persebaran data pada kolom-kolom yang ada.
- Menangani missing value pada data, dalam hal ini adalah data null.
- Menangani outlier atau pencilan pada data dengan menghapus data tersebut.
- Membuat sistem rekomendasi yang mampu memberikan rekomendasi yang mungkin dibutuhkan dan disukai oleh pengguna.
-
Secara garis besar proyek ini menggunakan metode Content Based Filtering dengan memanfaatkan beberapa algotima dalam prosesnya. Beberapa algoritma tersebut adalah :
- TF-IDF Vectorizer
- Cosine Similarity
Dataset yang digunakan dalam proyek ini merupakan dataset dari riwayat harga bensin dengan detail yang lengkap. Informasi mengenai dataset ini adalah sebagai berikut:
| Jenis | Keterangan |
|---|---|
| Sumber | Dataset: Kaggle |
| Dataset Owner | LAVANYA |
| Usability | 7.06 |
| Jenis dan Ukuran Berkas | 1.36 MB |
Dataset yang digunakan memiliki total 10841 record dalam setiap kolom. Dataset ini sendiri memiliki dengan 13 kolom (App, Category, Rating, Reviews, Size, Installs, Type, Price, Content_Rating, Genres, Last_Updated, Current_Ver, Android_Ver) yang memiliki 1487 missing value sebagian besar pada kolom Rating dan beberapa pada kolom Type, Content_Rating, Current_Ver, Android_Ver dengan informasi sebagai berikut :
- App : Nama Aplikasi
- Category : Jenis atau kategori yang dimiliki aplikasi
- Rating : Rata-rata penilaian yang diberikan oleh user
- Reviews : Jumlah komentar yang diberikan oleh user
- Size : Ukuran aplikasi
- Installs : Jumlah download/install aplikasi
- Type : Tipe aplikasi apakah gratis atau berbayar
- Price : Harga aplikasi ketika user ingin mendownloadnya
- Content_Rating : Kepada siapa aplikasi diperuntukkan
- Genres : Genre/tipe yang dimiliki oleh aplikasi
- Last_Updated : Waktu terakhir kali aplikasi diupdate
- Current_Ver : Versi yang dimiliki aplikasi saat ini
- Andriod_Ver : Versi minimal Android untuk bisa menjalankan aplikasi
- Menangani outlier
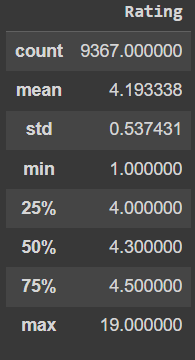
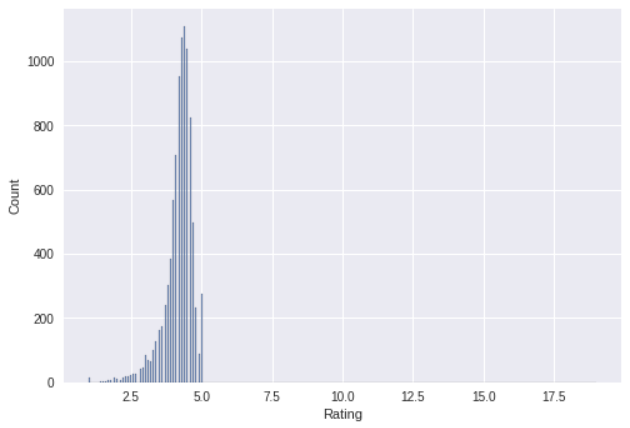
Dengan menggunakan metode histogram, dalam persebaran data di atas terlihat jelas bahwa terdapat sebuah outlier. Hal ini disebabkan karena seharusnya rating maksimal yang ada di Google Play Store adalah 5, dengan kata lain histogram seharunya hanya menunjukkan rating 0 - 5. Sementara melihat dua gambar di atas rating tertinggi yang dimiliki sebuah aplikasi adalah 19. Oleh karena itu kita akan menghapus aplikasi-aplikasi dengan rating lebih dari 5. Setelah melakukan penghapusan tehadap data outlier, maka didapatkan sebuah data baru dengan total 13 kolom di mana masing-masing kolom memiliki 10840 record.
- Menangani missing value pada kolom rating
Missing value dengan jumlah 1474 yang terdapat pada kolom rating tentu akan menjadi permasalahan dalam pemodelan. Jika kita menghapus 1474 baris dari 10840 baris data yang kita miliki tentu akan sangat disayangkan. Oleh karena itu kita akan memberikan rating berdasarkan rata-rata review pengguna pada aplikasi lain dengan rating tertentu. Berikut adalah rata-rata review pengguna berdasarkan rating aplikasi:

Sementara berikut adalah persebaran data review pada aplikasi dengan rating null :
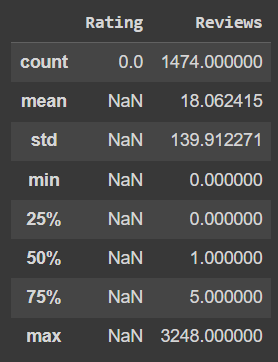
Melihat persebaran data di atas, aplikasi dengan rating null hanya mendapatkan review terbanyak sebesar 3248 review. Oleh karena itu dengan mempertimbangkan rata-rata review di atas kita akan memberikan rating 2 kepada semua aplikasi dengan rating null. Sehingga berikut adalah persebaran data pada kolom rating:
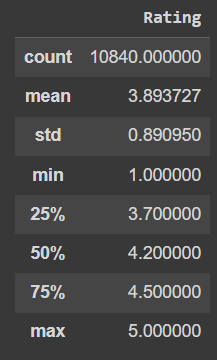
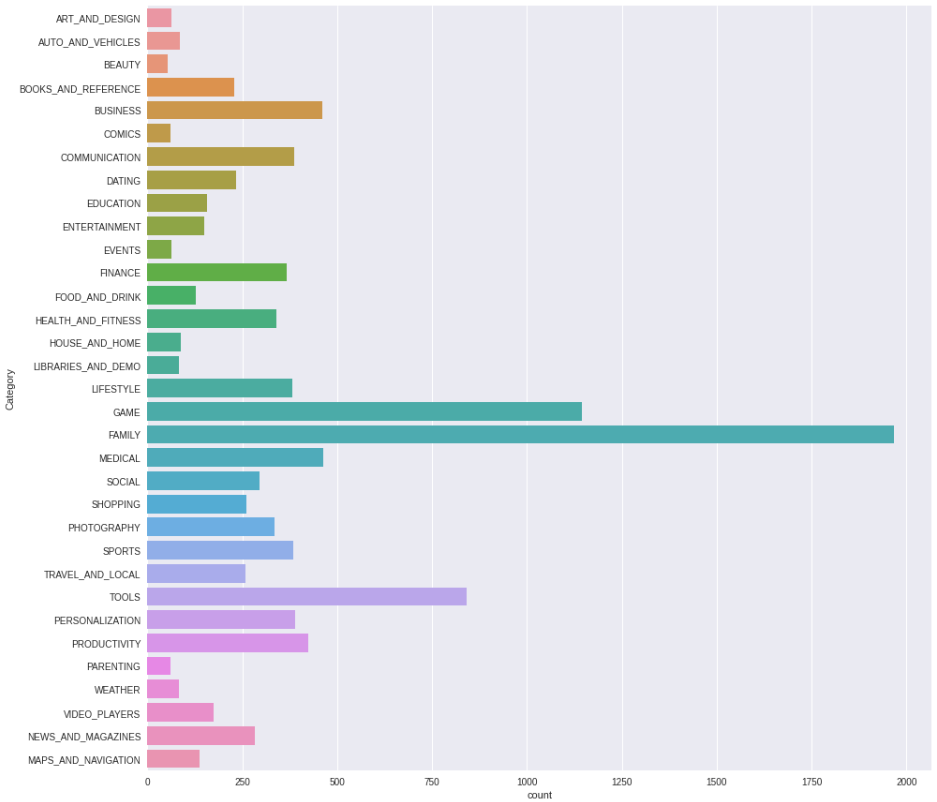
- Visualisasi kolom 'Category'
Sebagai kolom yang akan kita gunakan sebagai target atau acuan dalam menentukan rekomendasi, maka kita perlu melihat visualisasi data pada kolom 'Category' sebagai berikut:
- Visualisasi kolom 'Type'
Berikut adalah visualisasi kolom 'Type' dengan diagram pie guna melihat jumlah aplikasi berbayar dan gratis pada semua data.
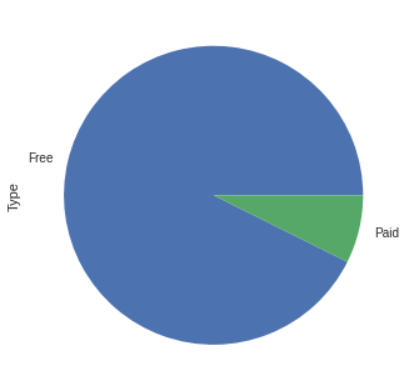
Dari diagram di atas, aplikasi gratis memiliki jumlah lebih besar yaitu sebanyak 10032 data, sedangkan aplikasi berbayar memiliki 797 data.
- Visualisasi kolom 'Content_Rating'
'Content_Rating' adalah kolom yang berisi informasi mengenai untuk siapa sebuah aplikasi diperuntukkan. Sebelumnya kita sudah melakukan penggabungan 'Content_Rating' bernilai 'Adults only 18+' kepada 'Mature 17+', serta 'Unrated' kepada 'Everyone'. Alasan penggabungan ini dikarenakan 'Content_Rating' dengan value 'Adults only 18+' dan 'Unrated' hanya memiliki jumlah yang sedikit. Berikut adalah visualisasi kolom 'Content_Rating' setelah pemrosesan dengan diagram pie:

- Visualisasi kolom 'Android_Ver'
Kolom 'Android_Ver' memiliki unique value yang cukup banyak di dalamnya. Oleh karena itu kita akan menggabungkan semua unique value yang berjumlah kurang dari 100 menjadi satu dalam sebuah value 'Other_Versions'. Berikut adalah visualisasi kolom 'Android_Ver' setelah dilakukan pemrosesan:
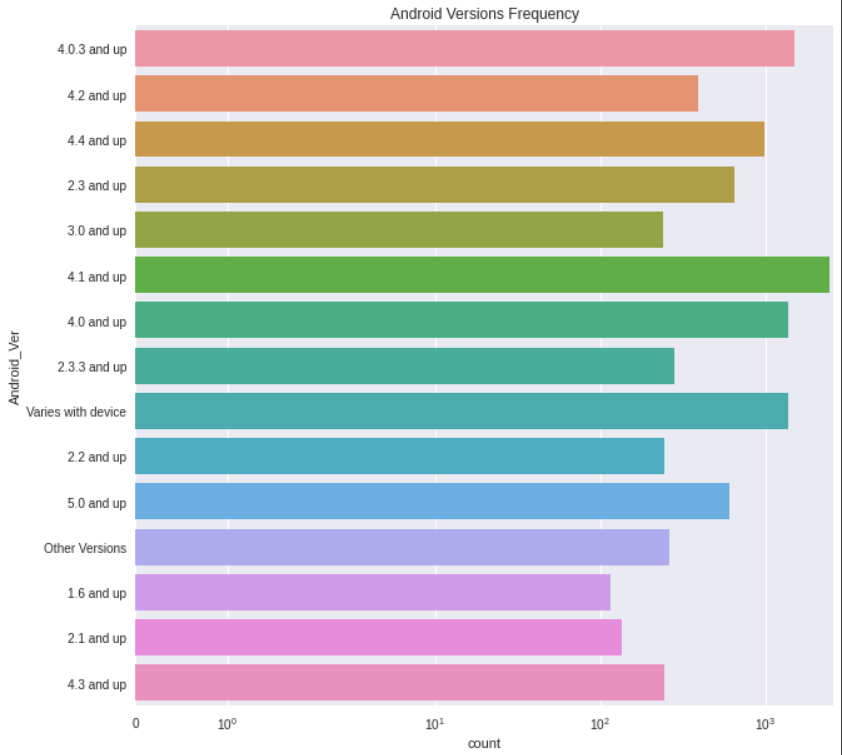
Berikut ini merupakan tahapan-tahapan dalam melakukan pra-pemrosesan data:
Pada kasus ini dalam menangani Missing Value kita menggunakan dua cara. Misiing value yang ada pada kolom Rating kita isi dengan rating 2, hal ini berdasarkan rata-rata review terhadap aplikasi dengan rating tertentu. Sementara missing value yang berada pada kolom Type, Content_Rating, Current_Ver, Android_Ver dilakukan penghapusan karena jumlahnya yang sedikit dan tidak mempengaruhi model.
Karena kita tidak memerlukan fitur Last_Updated dan Current_Ver kita akan menghapus fitur Last_Updated dan Current_Ver. Kita juga tidak memerlukan fitur Genre karena Category lebih mewakili jenis aplikasi daripada Genre.
Normalisasi data yang kita lakukan adalah dengan mengganti nama kolom yang memiliki spasi. Spasi pada kolom tersebut kita ganti dengan karakter '_'(underscore). Selain itu kita juga melakukan normalisasi pada kolom 'Size' dengan menghilangkan imbuhan 'M' dan 'k' serta mengonversi seluruh ukuran dalam satuan Mb. Kami juga melakukan penghapusan karakter '+' pada kolom 'Installs' dan karakter '$' pada kolom 'Price'.
Proses pemberian rekomendasi pada proyek ini menggunakan metode Content Based Filtering
Content Based Filtering merekomendasikan item yang mirip dengan item sebelumnya yang disukai atau dipilih oleh pengguna. Kemiripan item dihitung berdasarkan pada fitur-fitur yang ada pada item yang dibandingkan. Di sini kami membuat fungsi yang memiliki parameter sebagai berikut :
- app_name : Parameter ini berisi nama aplikasi yang kita cari rekomendasinya.
- similarity_data : Parameter ini berisi dataframe yang berisi similarity yang sebelumnya telah kita definisikan menggunakan cosine similarity
- items : Parameter ini berisi nama-nama fitur yang dimunculkan pada saat rekomendasi data sebagai tolak ukur kemiripan dan informasi aplikasi. Dalam kasus ini fitur yang kita gunakan adalah 'App', 'Category', 'Type', 'Content_Rating', dan 'Rating'
- k : Banyaknya aplikasi yang ingin kita rekomendasikan. Dalam hal ini kami membuat nilai default k dengan angka 5 sehingga sistem akan memberikan 5 rekomendasi aplikasi termirip.
- Efektif digunakan untuk mencari rekomendasi berdasarkan kemiripan sebuah aplikasi.
- Terbatasnya rekomendasi hanya pada item-item yang mirip sehingga tidak ada kesempatan untuk mendapatkan item yang tidak terduga.
Berikut adalah hasil pemodelan dengan memberikan 5 rekomendasi aplikasi berdasarkan aplikasi bernama 'Sketch - Draw & Paint' :


Pada bagian result and evaluation ini kita akan mengambil sebuah sampel rekomendasi berdasarkan aplikasi bernama 'Sketch - Draw & Paint'. Berikut adalah informasi dari aplikasi 'Sketch - Draw & Paint' :
Berdasarkan aplikasi tersebut, sistem yang kita bangun berhasil memberikan 5 rekomendasi sebagai berikut :
Mengingat kita mencari rekomendasi berdasarkan kategori yang dimiliki aplikasi, maka kita bisa mengevaluasinya menggunakan rumus berikut:
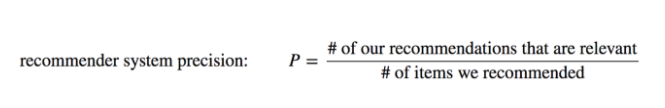
Berdasarkan rumus di atas kita bisa mengetahui presisi dari rekomendasi yang kita berikan. Kita telah memberikan 5 buah rekomendasi dan semuanya menghasilkan kategori yang sama yaitu ART_AND_DESIGN. Oleh karena itu dengan perhitungan sederhana dengan rumus di atas, maka presisi dari sistem yang kita miliki adalah 100%
Berdasarkan seluruh proses dalam proyek mulai dari penyiapan dataset hingga pemberian rekomendasi, akhirnya kita tiba pada kesimpulan dari keseluruhan jalannya proyek ini. Beberapa poin penting yang terdapat dalam proyek ini adalah sebagai berikut:
- Proses EDA (Exploratory Data Analysis) dilakukan dengan handling missing value berupa pengisian data null serta penghapusan data outliers.
- Normalisasi data dilakukan dengan mengganti spasi pada nama kolom menggunakan karakter '_'(underscore), konversi ukuran aplikasi dalam satuan Mb dan menghapus imbuhan 'M' dan 'k' pada kolom 'Size'. Selain itu normalisasi juga dilakukan dengan menghapus karakter '+' pada kolom 'Installs' dan karakter '$' pada kolom 'Price'.
- Melalui sebuah sampel yang kita ambil dari hasil perekomendasian, sistem yang kita buat memiliki presisi 100%. Artinya aplikasi yang direkomendasikan semuanya memiliki kategori yang sama dengan aplikasi yang kita masukkan.
Dari beberapa poin tersebut dapat ditarik sebuah kesimpulan di mana proyek yang telah kita buat berhasil memenuhi goal atau tujuan yang kita rumuskan di awal.
- Appbrain. (2021). Number of Android Apps on Google Play. Available at: https://www.appbrain.com/stats/number-of-android-apps.
- Mondi, Rhesa Havilah, Ardhi Wijayanto, dan Winarno. (2019). RECOMMENDATION SYSTEM WITH CONTENT-BASED FILTERING METHOD FOR CULINARY TOURISM IN MANGAN APPLICATION. ITSMART: Jurnal Ilmiah Teknologi dan Informasi.