-
数据结构与算法
- 重点掌握:数组、链表、栈/队列、哈希表、树(二叉树、AVL、红黑树)、堆、图、字符串操作。
- 高频算法:排序(快排、归并)、二分查找、DFS/BFS、动态规划、贪心算法、滑动窗口、双指针。
- 推荐资料:
- 书籍:《算法导论》《剑指Offer》
- 刷题平台:LeetCode(精选Top 100)、牛客网(国内企业真题)
- 学习技巧:按标签分类刷题(如动态规划),总结模板和常见优化方法。
- 三叶题单
- 算法模板
- Golang常用数据结构
-
计算机网络
- 核心概念:TCP/IP协议栈、HTTP/HTTPS、DNS、WebSocket、TCP三次握手/四次挥手、拥塞控制。
- 高频问题:HTTP状态码、RESTful API设计、Cookie/Session区别、HTTPS加密流程。
- 推荐资料:
- 书籍:《计算机网络:自顶向下方法》
- 文章:MDN Web Docs、阮一峰HTTP协议博客。
-
操作系统
- 核心内容:进程/线程、死锁、内存管理(分页/分段)、虚拟内存、文件系统、I/O模型。
- 高频问题:线程同步方式(锁、信号量)、进程间通信(IPC)、上下文切换开销。
- 推荐资料:
- 书籍:《现代操作系统》《Operating Systems: Three Easy Pieces》
- 视频:MIT 6.828(操作系统课程)。
-
数据库
- SQL:复杂查询(JOIN、子查询)、索引优化、事务ACID、隔离级别。
- NoSQL:Redis(数据结构、持久化)、MongoDB适用场景。
- 高频问题:索引原理(B+树)、慢查询优化、MVCC机制。
- 推荐资料:
- 书籍:《高性能MySQL》《Redis设计与实现》
- 工具:EXPLAIN分析SQL执行计划。
针对 Golang/Python/Java/C++ 四种编程语言的后端面试准备,以下是分语言的详细建议和重点方向:
- 语言特性
- 并发模型:
goroutine、channel(缓冲/非缓冲)、select、sync包(Mutex、WaitGroup)。 - 内存管理:逃逸分析、GC三色标记法、内存对齐。
- 接口与反射:接口的隐式实现、
reflect包的原理。
- 并发模型:
- 高频问题:
defer的执行顺序与陷阱(如defer与闭包变量捕获)。slice与map的底层实现(扩容机制、并发安全)。context包的使用场景(超时控制、取消传播)。
- 面试侧重:
- 重点展示对高并发场景的理解(如用
channel实现生产者-消费者模型)。 - 准备一个用Go实现的并发项目(如分布式任务调度系统)。
- 重点展示对高并发场景的理解(如用
- 微服务框架:Gin(路由原理、中间件机制)、Echo。
- 生态工具:gRPC(Protocol Buffers)、Go Modules依赖管理。
- 书籍:《Go语言设计与实现》《Go语言高级编程》
- 源码:阅读标准库源码(如
net/http、sync包)。 - 实战:用Go实现高并发服务(如WebSocket聊天室)。
- 项目: Golang面试合集
- 项目: Golang算法模板
- 语言特性
- 动态类型:
鸭子类型、MRO(方法解析顺序)、GIL全局解释器锁。 - 高级语法:装饰器、生成器、上下文管理器、元类(metaclass)。
- 内存管理:引用计数、垃圾回收机制、
__slots__优化。
- 动态类型:
- 高频问题:
- 多线程与多进程的区别(GIL的影响)。
- 深浅拷贝的实现原理(
copy模块)。 - 协程与异步编程(
asyncio、async/await)。
- 面试侧重:
- 强调开发效率与脚本能力(如自动化工具开发经验)。
- 解释GIL的局限性,并说明如何绕过(如多进程+消息队列)。
- Web框架:Django(ORM原理、中间件)、Flask(请求上下文、蓝图)。
- 数据处理:Pandas、NumPy(向量化操作)。
- 书籍:《流畅的Python》《Effective Python》
- 学习:Python官方文档(注重CPython实现细节)。
- 实战:用异步框架(如FastAPI)构建高吞吐API服务。
- 语言特性
- JVM:内存模型(堆、栈、方法区)、类加载机制、GC算法(CMS、G1)。
- 并发编程:
synchronized、volatile、ThreadLocal、AQS(AbstractQueuedSynchronizer)。 - 集合框架:
HashMap(红黑树优化)、ConcurrentHashMap(分段锁/CAS)。
- 高频问题:
ArrayList与LinkedList的时间复杂度对比。- Spring框架的依赖注入原理(BeanFactory vs. ApplicationContext)。
- JVM调优实战(OOM排查、GC日志分析)。
- 面试侧重:
- 深入JVM和框架源码(如Spring AOP的动态代理实现)。
- 结合分布式系统经验(如用Spring Cloud实现微服务)。
- 核心语法:集合框架(HashMap源码)、多线程(线程池、CAS)、JVM内存模型、垃圾回收算法。
- 框架与生态:Spring(IoC/AOP)、Spring Boot自动配置、MyBatis原理。
- 高频问题:
- HashMap扩容机制
- ConcurrentHashMap如何保证线程安全
- Spring Bean生命周期
- JVM调优实战经验
- 推荐资料:
- 书籍:《Effective Java》《深入理解Java虚拟机》
- 源码:JDK核心类库、Spring Framework源码。
- 主流框架:Spring Boot(自动配置原理)、MyBatis(动态代理实现SQL映射)。
- 微服务:Spring Cloud(服务注册发现、熔断器Hystrix)。
- 书籍:《深入理解Java虚拟机》《Java并发编程实战》
- 源码:JDK集合框架、Spring核心模块(如
spring-core)。
- 语言特性
- 内存管理:
new/delete与malloc/free区别、智能指针(unique_ptr、shared_ptr)。 - 面向对象:虚函数表(vtable)、多重继承的陷阱、RAII机制。
- 模板与STL:模板元编程、容器(
vector、map)的底层实现。
- 内存管理:
- 高频问题:
- 移动语义(
std::move、右值引用)。 - 虚析构函数的作用。
const关键字的用法(常量指针 vs. 指针常量)。
- 移动语义(
- 面试侧重:
- 突出内存管理和性能优化能力(如避免内存泄漏的方案)。
- 准备底层项目(如实现一个简易数据库或网络库)。
- 常用库:Boost(智能指针、线程池)、Qt(信号槽机制)。
- 高性能场景:内存池设计、零拷贝技术。
- 书籍:《Effective C++》《C++ Primer》
- 学习:C++标准文档(C++11/14/17新特性)。
- 实战:手写STL容器(如简易
vector)。 - 面经: C/C++后端开发面经
- 基础设计:短链生成、计数器、分布式ID生成、缓存设计(LRU)。
- 进阶设计:秒杀系统、社交网络(关注/粉丝)、分布式文件存储、消息队列(Kafka/RabbitMQ)。
- 方法论:
- 明确需求(QPS、数据量、一致性要求)
- 设计核心组件(数据库分库分表、缓存策略、负载均衡)
- 解决瓶颈(热点数据、分布式锁、容灾备份)
- 推荐资料:
- 书籍:《数据密集型应用系统设计》
- 课程:Grokking the System Design Interview(英文)
- 实战:参考GitHub开源项目(如TinyURL)。
三次握手确保建立可靠连接。四次挥手确保断开数据不丢失。
- 特点:
- 唯一标识表中每一行数据,不允许重复和
NULL值。 - 每个表只能有一个主键索引。
- 默认使用 B+Tree 结构。
- 唯一标识表中每一行数据,不允许重复和
- 语法:
CREATE TABLE users ( id INT PRIMARY KEY, -- 主键索引 name VARCHAR(50) );
- 特点:
- 确保列的值唯一,允许
NULL值(但只能有一个NULL)。 - 可以创建多个唯一索引。
- 常用于避免重复数据(如邮箱、手机号)。
- 确保列的值唯一,允许
- 语法:
CREATE UNIQUE INDEX idx_email ON users(email);
- 特点:
- 最基本的索引类型,无唯一性约束。
- 用于加速查询,但允许重复值和
NULL。
- 语法:
CREATE INDEX idx_name ON users(name);
- 特点:
- 对多个列联合建立索引,支持多条件查询。
- 遵循 最左前缀原则(查询条件需包含最左列才能触发索引)。
- 语法:
CREATE INDEX idx_name_age ON users(name, age);
- 示例:
-- 以下查询会使用索引: SELECT * FROM users WHERE name = 'Alice'; SELECT * FROM users WHERE name = 'Bob' AND age = 30; -- 以下查询不会使用索引(缺少最左列 name): SELECT * FROM users WHERE age = 25;
- 特点:
- 用于全文搜索(如
MATCH ... AGAINST语句),支持文本字段(CHAR/VARCHAR/TEXT)。 - 仅适用于 MyISAM 和 InnoDB(MySQL 5.6+)引擎。
- 用于全文搜索(如
- 语法:
CREATE FULLTEXT INDEX idx_content ON articles(content); - 示例:
SELECT * FROM articles WHERE MATCH(content) AGAINST('database' IN NATURAL LANGUAGE MODE);
- 特点:
- 对字符串的前
N个字符建立索引,减少存储空间。 - 需平衡前缀长度和选择性(唯一性)。
- 对字符串的前
- 语法:
CREATE INDEX idx_name_prefix ON users(name(10)); -- 前10个字符
- 特点:
- 用于地理空间数据类型(如
GEOMETRY,POINT,POLYGON)。 - 支持空间查询(如
ST_Contains,ST_Distance)。 - 仅适用于 MyISAM 引擎(InnoDB 从 MySQL 5.7+ 支持)。
- 用于地理空间数据类型(如
- 语法:
CREATE SPATIAL INDEX idx_location ON places(coordinates);
- 特点:
- 索引包含查询所需的所有列,避免回表查询。
- 显著提升查询性能。
- 示例:
-- 若索引是 (name, age),查询只需 name 和 age: SELECT name, age FROM users WHERE name = 'Alice';
| 索引类型 | InnoDB | MyISAM | MEMORY |
|---|---|---|---|
| B-Tree | ✅ | ✅ | ✅ |
| 全文索引 | ✅ (5.6+) | ✅ | ❌ |
| 空间索引 | ✅ (5.7+) | ✅ | ❌ |
| 哈希索引 | ❌ | ❌ | ✅ |
- 主键索引:必须为表显式或隐式定义。
- 高频查询字段:对
WHERE,JOIN,ORDER BY涉及的列建索引。 - 避免过度索引:索引会降低写操作(INSERT/UPDATE/DELETE)性能。
- 组合索引优化:优先选择区分度高的列作为最左前缀。
- 基于内存操作:Redis的绝大部分操作在内存里就可以实现,数据也存在内存中,与传统的磁盘文件操作相比减少了IO,提高了操作的速度。
- 高效的数据结构:Redis有专门设计了STRING、LIST、HASH等高效的数据结构,依赖各种数据结构提升了读写的效率。
- 采用单线程:单线程操作省去了上下文切换带来的开销和CPU的消耗,同时不存在资源竞争,避免了死锁现象的发生。
- I/O多路复用:采用I/O多路复用机制同时监听多个Socket,根据Socket上的事件来选择对应的事件处理器进行处理。
Redis默认情况下是内存数据库,数据是存储在内存中的。为了防止断电或其他意外情况导致数据丢失,Redis提供了两种持久化机制:
- RDB(Redis DataBase):
- 原理: 将Redis在某个时间点的数据(快照)以二进制形式保存到硬盘中。
- 触发方式:
- 手动触发:使用SAVE或BGSAVE命令。
- 自动触发:配置Redis,在一定时间内有N多条数据被修改时自动触发。
- 优点:文件恢复速度快,适用于数据恢复。配置简单。
- 缺点:数据可能丢失:如果在两次RDB快照之间数据发生变化,而没有来得及保存,那么发生故障时会丢失部分数据。
- AOF(Append Only File):
- 原理: 将所有的写操作命令以Redis协议的格式追加到一个文件中。
- 触发方式:
- 每秒同步:每秒将缓冲区中的数据写入AOF文件一次。
- 每修改同步:每次写入都同步到AOF文件。
- 同步关闭:在关闭服务器时才写入AOF文件。
- 优点:数据安全性高,数据丢失的概率较低。支持数据追加,效率高。
- 缺点:AOF文件可能会变得很大,影响性能。文件同步频率越高,性能影响越大。
建议:
- 同时开启RDB和AOF: RDB用于快速恢复数据,AOF用于保证数据不丢失。
- 配置合理的RDB保存策略: 根据业务需求设置RDB保存的时间间隔和触发条件。
- 配置合适的AOF同步策略: 在保证数据安全性的前提下,选择合适的AOF同步频率。
- 主从复制:
- 原理: 主节点负责写操作,从节点负责读操作,主节点将数据同步给从节点。
- 优点:读写分离,提高性能。数据冗余,提高可用性。
- 缺点:主节点故障时,需要手动切换。
- 哨兵模式:
- 原理: 哨兵是Redis的监控工具,它可以监控多个Redis实例,并在主节点故障时自动进行故障转移。
- 优点:自动故障转移,提高可用性。支持主从复制配置。
- 缺点:配置相对复杂。
- Redis Cluster:
- 原理: 将数据分片存储在多个节点上,每个节点负责一部分数据。
- 优点:线性扩展,提高性能。高可用性。
- 缺点:配置复杂,数据迁移成本高。
- 主从复制一致性:
- 部分同步:主节点写完数据后立即同步到从节点。
- 全同步:主节点收到所有从节点的ack确认后才写入数据。
- 哨兵模式故障转移:哨兵会选择一个从节点作为新的主节点,并进行数据同步。
- Redis Cluster数据一致性:使用一致性哈希算法来分配数据。支持故障转移和数据迁移。
定义:大量缓存数据同时过期,导致所有请求直接访问数据库,引发数据库压力激增甚至崩溃。
解决策略:
- 随机过期时间:为不同缓存设置不同的过期时间(例如基础过期时间 + 随机偏移)。
// 示例:设置过期时间为 60分钟 ± 随机10分钟 int expireTime = 60 * 60 + (int)(Math.random() * 10 * 60);
- 永不过期 + 异步更新:
- 缓存不设过期时间,通过后台线程定期更新。
- 结合互斥锁,避免多个线程同时更新。
- 多级缓存:使用本地缓存(如 Caffeine)结合分布式缓存(如 Redis),降低集体失效风险。
- 熔断降级:当数据库压力过大时,启用限流或返回默认值,保护系统可用性。
定义:某个热点数据过期的瞬间,大量并发请求直接穿透到数据库,导致数据库负载骤增。
解决策略:
- 互斥锁(Mutex Lock):
- 当缓存失效时,使用分布式锁(如 Redis 的
SETNX),确保只有一个线程加载数据。
public String getData(String key) { String data = cache.get(key); if (data == null) { if (lock.tryLock()) { // 获取分布式锁 try { data = db.load(key); // 查询数据库 cache.set(key, data, expireTime); } finally { lock.unlock(); } } else { // 等待其他线程加载完成 Thread.sleep(100); return cache.get(key); } } return data; }
- 当缓存失效时,使用分布式锁(如 Redis 的
- 逻辑过期:
- 缓存数据永不过期,但存储逻辑过期时间。当发现数据过期时,异步更新缓存。
- 热点数据预加载:针对高频访问数据,提前刷新缓存,避免自然过期。
定义:请求访问不存在的数据(如非法 ID),绕过缓存直接查询数据库,导致无效查询堆积。
解决策略:
- 布隆过滤器(Bloom Filter):
- 在缓存层前加布隆过滤器,快速判断数据是否存在,拦截无效请求。
if (!bloomFilter.mightContain(key)) { return null; // 直接返回,不查询缓存或数据库 }
- 缓存空值:对查询结果为
NULL的请求,缓存空值并设置较短过期时间(如 5 分钟)。if (data == null) { cache.set(key, "NULL", 5 * 60); // 缓存空值 }
- 参数校验:在业务层对请求参数进行合法性检查(如 ID 范围、格式)。
- 限流与黑名单:对频繁访问无效 Key 的 IP 或用户进行限流或加入黑名单。
| 问题类型 | 触发条件 | 核心解决思路 | 典型方案 |
|---|---|---|---|
| 缓存雪崩 | 大量缓存同时失效 | 分散过期时间、多级缓存、熔断降级 | 随机过期时间、多级缓存、异步更新 |
| 缓存击穿 | 热点数据过期 | 互斥锁、逻辑过期、热点预加载 | 分布式锁、逻辑过期时间、后台更新线程 |
| 缓存穿透 | 查询不存在的数据 | 拦截无效请求、缓存空值、参数校验 | 布隆过滤器、缓存空值、请求参数校验 |
- 监控与预警:实时监控缓存命中率、数据库 QPS,及时发现异常。
- 组合策略:根据业务场景混合使用上述方案(如布隆过滤器 + 空值缓存 + 互斥锁)。
- 压测验证:通过模拟高并发场景,验证解决方案的有效性。
func main() {
m := make(map[string]int)
go func() {
for {
m["blog"] = 1
}
}()
go func() {
for {
fmt.Println(m["blog"])
}
}()
select{} // block-forever trick
}
// fatal error: concurrent map read and map writefunc main() {
var syncMap sync.Map
// store a key-value pair
syncMap.Store("blog", "VictoriaMetrics")
// load a value by key "blog"
value, ok := syncMap.Load("blog")
fmt.Println(value, ok)
// delete a key-value pair by key "blog"
syncMap.Delete("blog")
value, ok = syncMap.Load("blog")
fmt.Println(value, ok)
}
// Output:
// VictoriaMetrics true
// <nil> falseGo语言中channel的底层实现原理可以分为以下几个关键部分:
在Go的运行时(runtime)中,每个channel由hchan结构体表示,定义在runtime/chan.go中:
type hchan struct {
qcount uint // 当前缓冲区中的数据量
dataqsiz uint // 缓冲区大小(容量)
buf unsafe.Pointer // 指向环形缓冲区的指针
elemsize uint16 // 元素大小
closed uint32 // channel是否已关闭(0-未关闭,1-已关闭)
elemtype *_type // 元素类型信息(用于类型检查)
sendx uint // 发送索引(缓冲区中的位置)
recvx uint // 接收索引(缓冲区中的位置)
recvq waitq // 接收等待队列(sudog链表)
sendq waitq // 发送等待队列(sudog链表)
lock mutex // 互斥锁,保护channel的线程安全
}- 有缓冲channel:数据存储在
buf指向的环形队列中,通过sendx和recvx跟踪写入和读取位置。 - 无缓冲channel:
buf为空,发送和接收操作直接通过goroutine间的数据拷贝完成。
- 缓冲区未满:数据直接写入缓冲区,更新
sendx。 - 缓冲区已满:
- 当前goroutine被打包为
sudog,加入sendq队列。 - goroutine进入等待状态,释放锁,触发调度器切换执行其他goroutine。
- 当前goroutine被打包为
- 有接收者等待:直接将数据拷贝到接收者,唤醒接收goroutine。
- 缓冲区非空:从缓冲区读取数据,更新
recvx。 - 缓冲区为空:
- 当前goroutine打包为
sudog,加入recvq队列。 - goroutine进入等待状态,释放锁,等待发送者唤醒。
- 当前goroutine打包为
- 有发送者等待:直接从发送者拷贝数据,唤醒发送goroutine。
waitq:双向链表,存储等待的goroutine(sudog)。sudog:表示一个等待中的goroutine,包含:- 指向goroutine的指针。
- 等待的channel和操作类型(发送/接收)。
- 数据内存地址(用于直接拷贝)。
- 设置
closed标志为1。 - 唤醒所有
sendq和recvq中的等待goroutine:- 发送者:触发panic(向已关闭channel发送数据)。
- 接收者:返回零值和
false(表示channel已关闭)。
- 发送和接收必须同步配对,数据直接从发送者拷贝到接收者,不经过缓冲区。
- 若对方未就绪,当前goroutine加入等待队列。
- 非阻塞检查:遍历所有case,检查channel是否可操作。
- 随机选择:若多个case就绪,随机选择一个执行(避免饥饿)。
- 等待机制:若所有case未就绪,将当前goroutine加入所有channel的等待队列,任一channel就绪后触发唤醒。
- 直接内存拷贝:避免数据在缓冲区和goroutine栈之间的额外复制。
- 锁粒度控制:通过互斥锁(
lock)保护hchan状态,但等待队列的操作会短暂释放锁,减少竞争。
-
创建channel:
ch := make(chan int, 3) // 创建容量为3的缓冲channel
- 分配
hchan结构体,初始化缓冲区、锁和队列。
- 分配
-
发送数据:
ch <- 42
- 加锁 → 缓冲区有空位 → 写入数据 → 解锁。
- 若缓冲区满,当前goroutine加入
sendq并阻塞。
-
接收数据:
val := <-ch
- 加锁 → 缓冲区有数据 → 读取数据 → 解锁。
- 若缓冲区空,当前goroutine加入
recvq并阻塞。
Go的channel通过hchan结构体管理缓冲区、同步锁和等待队列,实现高效的goroutine间通信:
- 有缓冲channel:基于环形队列的FIFO操作。
- 无缓冲channel:直接goroutine间数据传递。
- 同步机制:依赖互斥锁和等待队列,结合调度器实现阻塞与唤醒。
- 关闭操作:通过标志位和唤醒所有等待goroutine处理。
这种设计保证了channel在并发场景下的线程安全和高效性。
func f1() (result int) {
defer func() {
result++
}()
return 0
}
func f2() (r int) {
t := 5
defer func() {
t = t + 5
}()
return t
}
func f3() (r int) {
defer func(r int) {
r = r + 5
}(r)
return 1
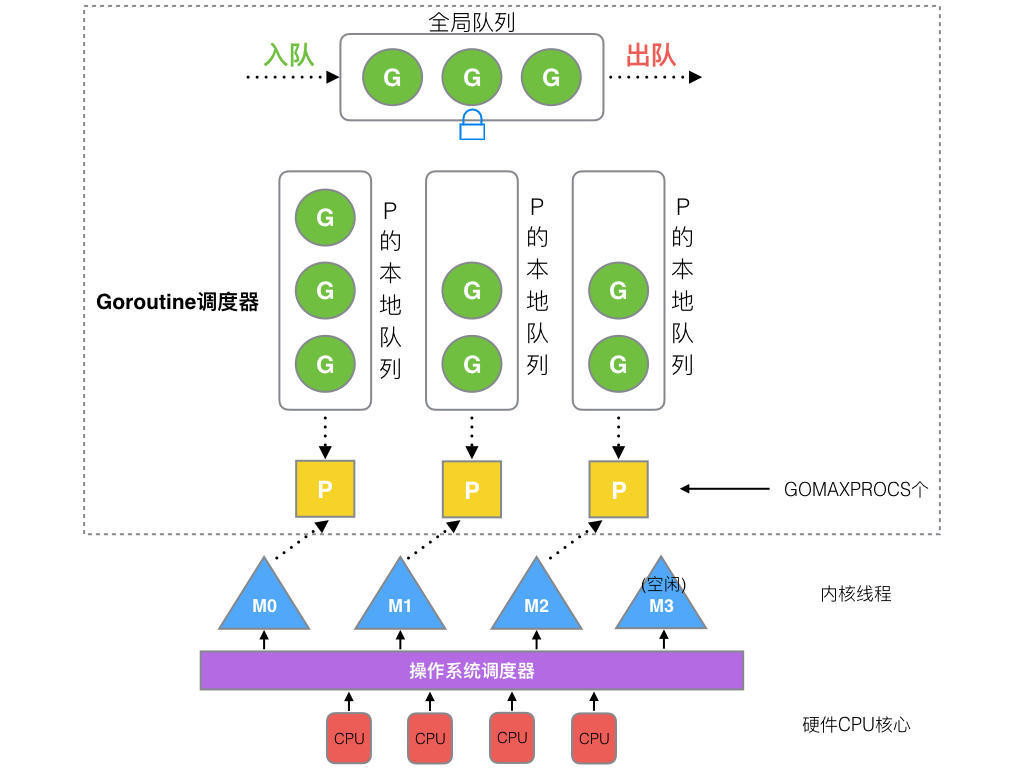
}G表示Goroutine协程 M表示OS线程 P表示Processor 处理器
在 Go 语言中,make 和 new 是两个用于内存分配的内置函数,但它们的使用场景和底层行为有明显区别。以下是它们的详细对比及内存分配位置的解释:
| 特性 | new(T) |
make(T, args...) |
|---|---|---|
| 作用对象 | 适用于任何类型(值类型、引用类型)。 | 仅适用于 slice、map、channel 三种引用类型。 |
| 返回值 | 返回 *T(指向类型 T 的指针)。 |
返回初始化后的 T 类型(非指针)。 |
| 初始化行为 | 分配内存并返回指向零值的指针。 | 分配内存并初始化数据结构(如分配底层数组、哈希表等)。 |
| 典型用例 | 创建值类型的指针(如 int、struct)。 |
创建引用类型的实例(如 []int、map[int]bool)。 |
// 使用 new
ptr := new(int) // ptr 是 *int 类型,指向 0
s := new([]int) // s 是 *[]int 类型,指向 nil 的 slice
// 使用 make
slice := make([]int, 10) // 创建长度为 10 的 slice
m := make(map[string]int) // 创建空的 map
ch := make(chan int) // 创建无缓冲的 channelGo 的内存分配由编译器通过 逃逸分析(Escape Analysis) 自动决定,规则如下:
- 栈分配:
- 如果变量的生命周期仅在函数内部,且未逃逸到函数外部,则优先分配在栈上。
- 栈分配速度快,但空间有限(适合小对象或短生命周期变量)。
- 堆分配:
- 如果变量的生命周期可能超出函数范围(如被全局变量引用或返回给调用方),则分配在堆上。
- 堆分配速度慢,但空间大(适合大对象或长生命周期变量)。
-
new的分配行为:new(T)返回的指针可能分配在栈或堆上,具体取决于是否逃逸。
func foo() *int { x := new(int) // x 逃逸到堆上 *x = 42 return x }
- 如果指针未逃逸(仅在函数内使用),可能分配在栈上:
func bar() { x := new(int) // x 可能分配在栈上 *x = 42 // x 未被外部引用 }
-
make的分配行为:slice、map、channel的底层结构(如slice的数组)通常分配在堆上,因为它们需要动态扩容或跨函数共享。
func createSlice() []int { s := make([]int, 100) // 底层数组逃逸到堆上 return s }
通过 go build -gcflags="-m" 可以查看变量的逃逸情况:
package main
func main() {
a := new(int) // 测试 new
*a = 1
b := make([]int, 10) // 测试 make
b[0] = 2
}$ go build -gcflags="-m" main.go
# command-line-arguments
./main.go:4:10: new(int) does not escape # a 未逃逸,可能分配在栈上
./main.go:7:13: make([]int, 10) escapes to heap # b 的底层数组逃逸到堆| 函数 | 适用类型 | 返回值 | 初始化行为 | 内存分配位置 |
|---|---|---|---|---|
new |
所有类型 | 指针 | 分配零值 | 由逃逸分析决定(栈/堆) |
make |
slice、map、channel |
实例 | 初始化数据结构 | 通常堆(底层结构逃逸) |
new返回指针,make返回实例。make专用于引用类型,确保数据结构可用。- 内存分配位置由逃逸分析决定,
make创建的底层结构通常逃逸到堆。
这个题目要求我们使用Go语言实现一个程序,在并发环境下顺序输出1到100的数字,同时限制最多只有10个goroutine同时运行。
package main
/*
并发顺序输出1到100的Go实现
这个题目要求我们使用Go语言实现一个程序,在并发环境下顺序输出1到100的数字,同时限制最多只有10个goroutine同时运行。
*/
import "sync"
// Counter 定义一个结构体来保存当前数字和锁
type Counter struct {
current int
mu sync.Mutex
}
// 定义一个函数来输出数字
func (c *Counter) printNumber(wg *sync.WaitGroup) {
//defer wg.Done() // 在函数结束时通知WaitGroup
defer func() {
if c.current > 100 {
wg.Done()
}
}()
// 获取锁
c.mu.Lock()
defer c.mu.Unlock() // 在函数结束时释放锁
// 如果当前数字小于等于100,则输出数字并增加当前数字
if c.current <= 100 {
println(c.current)
c.current++
}
}
// 定义一个函数来控制并发输出
func (c *Counter) run() {
var wg sync.WaitGroup
wg.Add(10) // 设置WaitGroup计数器为10
// 创建10个goroutine
for i := 0; i < 10; i++ {
go func() {
for {
c.printNumber(&wg) // 调用打印函数
if c.current > 100 { // 如果当前数字大于100,则退出循环
break
}
}
}()
}
wg.Wait() // 等待所有goroutine完成
}
func main() {
counter := &Counter{current: 1} // 初始化Counter结构体
counter.run() // 调用run函数开始输出数字
}TCP拥塞控制是确保网络稳定和高效运行的核心机制,其通过动态调整发送速率来避免网络拥塞。以下是TCP拥塞控制的分步解释:
- 避免网络过载:防止因发送方速率过快导致路由器或链路缓冲区溢出。
- 公平性:多连接共享带宽时,确保各连接公平竞争。
- 高效性:最大化网络吞吐量,最小化延迟和丢包。
TCP拥塞控制主要包含四个算法:慢启动、拥塞避免、快速重传和快速恢复,通过调整拥塞窗口(cwnd) 控制发送速率。
-
目的:探测网络容量,快速找到可用带宽。
-
规则:
- 初始时,拥塞窗口
cwnd = 1 MSS(最大报文段大小)。 - 每收到一个确认(ACK),
cwnd增加1 MSS(指数增长)。 - 当
cwnd达到慢启动阈值(ssthresh)时,进入拥塞避免阶段。 - 若发生超时重传(Timeout),重置
cwnd = 1 MSS,ssthresh = cwnd/2,重启慢启动。
- 初始时,拥塞窗口
-
示例:
cwnd变化:1 → 2 → 4 → 8 → 16(每RTT翻倍)
-
目的:避免窗口增长过快导致拥塞。
-
规则:
- 当
cwnd >= ssthresh时,进入拥塞避免阶段。 - 每收到一个ACK,
cwnd增加1/cwndMSS(线性增长)。 - 若发生超时重传,重置
cwnd = 1 MSS,ssthresh = cwnd/2,重启慢启动。
- 当
-
示例:
cwnd变化:16 → 17 → 18 → 19(每RTT增加1)
- 触发条件:收到3个重复ACK(同一数据包的冗余确认)。
- 规则:
- 立即重传丢失的报文,无需等待超时。
- 设置
ssthresh = max(cwnd/2, 2 MSS)。 - 进入快速恢复阶段。
- 目的:避免因单个丢包导致窗口骤降。
- 规则:
- 设置
cwnd = ssthresh + 3 MSS(补偿已确认的3个重复ACK)。 - 每收到一个重复ACK,
cwnd增加1 MSS。 - 当收到新数据的ACK时,设置
cwnd = ssthresh,进入拥塞避免阶段。
- 设置
不同TCP版本在拥塞控制细节上有所差异:
| 算法 | 特点 |
|---|---|
| TCP Tahoe | 任何丢包(超时或重复ACK)均触发慢启动,无快速恢复。 |
| TCP Reno | 引入快速恢复,仅超时触发慢启动,重复ACK触发快速重传和快速恢复。 |
| TCP NewReno | 优化快速恢复,支持处理多个包丢失的场景,避免多次重传导致窗口过度缩减。 |
| TCP BBR | 基于带宽和延迟估计的动态调整,替代传统丢包驱动模型,减少缓冲区膨胀问题。 |
- MSS(Maximum Segment Size):单个报文最大长度(如1460字节)。
- RTT(Round-Trip Time):数据往返时间。
- ssthresh(Slow Start Threshold):慢启动阈值,初始通常为较大值(如65535字节)。
- 正常传输:
- 慢启动阶段:
cwnd指数增长至ssthresh。 - 拥塞避免阶段:
cwnd线性增长。
- 慢启动阶段:
- 丢包处理:
- 若发生超时:
cwnd重置为1,重启慢启动。 - 若收到3个重复ACK:触发快速重传和快速恢复。
- 若发生超时:
- 慢启动:每RTT窗口翻倍
[ cwnd_{new} = cwnd + \text{ACK数量} \times MSS ] - 拥塞避免:每RTT窗口增加1 MSS
[ cwnd_{new} = cwnd + \frac{MSS}{cwnd} ]
TCP拥塞控制通过动态调整发送窗口,平衡网络吞吐量与稳定性:
- 慢启动快速探测带宽,拥塞避免谨慎增长。
- 快速重传/恢复减少丢包对性能的影响。
- 不同算法变种针对特定场景优化,如BBR适用于高带宽延迟积网络。
- 经常搜索的列上建索引
- 作为主键的列上要建索引
- 经常需要连接(where子句)的列上
- 经常需要排序的列
- 经常需要范围查找的列
哪些列不适合建索引?
- 很少查询的列
- 更新很频繁的列
- 数据值的取值比较少的列(比如性别)
数据库的索引是使用B+树来实现的。
(为什么要用B+树,为什么不用红黑树和B树)
B+树是一种特殊的平衡多路树,是B树的优化改进版本,它把所有的数据都存放在叶节点上,中间节点保存的是索引。这样一来相对于B树来说,减少了数据对中间节点的空间占用,使得中间节点可以存放更多的指针,使得树变得更矮,深度更小,从而减少查询的磁盘IO次数,提高查询效率。另一个是由于叶节点之间有指针连接,所以可以进行范围查询,方便区间访问。
而红黑树是二叉的,它的深度相对B+树来说更大,更大的深度意味着查找次数更多,更频繁的磁盘IO,所以红黑树更适合在内存中进行查找。
这都是由于B+树和B具有不同的存储结构所造成的区别,以一个m阶树为例。
- 关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
- 存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
- 分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
- 查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。
B+树优点:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引,而B树则常用于文件索引。
数据库事务是指逻辑上对数据的一种操作,这个事务要么全部成功,要么全部失败。
数据库事务的原子性是指:事务是一个不可分割的工作单位,这组操作要么全部发生,要么全部不发生。
数据库事务的一致性是指:在事务开始以前,数据库中的数据有一个一致的状态。在事务完成后,数据库中的事务也应该保持这种一致性。事务应该将数据从一个一致性状态转移到另一个一致性状态。
比如在银行转账操作后两个账户的总额应当不变。
数据库事务的隔离性要求数据库中的事务不会受另一个并发执行的事务的影响,对于数据库中同时执行的每个事务来说,其他事务要么还没开始执行,要么已经执行结束,它都感觉不到还有别的事务正在执行。
数据库事务的持久性要求事务对数据库的改变是永久的,哪怕数据库发生损坏都不会影响到已发生的事务。
如果事务没有完成,数据库因故断电了,那么重启后也应该是没有执行事务的状态,如果事务已经完成后数据库断电了,那么重启后就应该是事务执行完成后的状态。
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
比如 学生 选课(包括很多课程) 就不符合第一范式
在满足第一范式的前提下,(主要针对联合主键而言)第二范式需要确保数据库表中的每一列都和主键的所有成员直接相关,由整个主键才能唯一确定,而不能只与主键的某一部分相关或者不相关。
比如一张学生信息表,由主键(学号)可以唯一确定一个学生的姓名,班级,年龄等信息。但是主键 (学号,班级) 与列 姓名,班主任,教室 就不符合第二范式,因为班主任跟部分主键(班级)是依赖关系
在满足第二范式的前提下,第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。非主键的列不能确定其他列,列与列之间不能出现传递依赖。
比如一张学生信息表,主键是(学号)列包括 姓名,班级,班主任 就不符合第三范式,因为非主键的列中 班主任 依赖于 班级
主键有可能是由多个属性组合成的复合主键,那么多个主键之间不能有传递依赖。也就是复合主键之间谁也不能决定谁,相互之间没有关系。
IO过程包括两个阶段:(1)内核从IO设备读写数据和(2)进程从内核复制数据
调用IO操作的时候,如果缓冲区空或者满了,调用的进程或者线程就会处于阻塞状态直到IO可用并完成数据拷贝。
调用IO操作的时候,内核会马上返回结果,如果IO不可用,会返回错误,这种方式下进程需要不断轮询直到IO可用为止,但是当进程从内核拷贝数据时是阻塞的。
同时监听多个描述符,一旦某个描述符IO就绪(读就绪或者写就绪),就能够通知进程进行相应的IO操作,否则就将进程阻塞在select或者epoll语句上。
同步IO模型包括阻塞IO,非阻塞IO和IO多路复用。特点就是当进程从内核复制数据的时候都是阻塞的。
在检测IO是否可用和进程拷贝数据的两个阶段都是不阻塞的,进程可以做其他事情,当IO完成后内核会给进程发送一个信号。