articles
├── 01.md ✅
├── 02.md ✅
├── 03.md ✅
├── 04.md ✅
├── 05.md ✅
├── 06.md ✅
├── 07.md ✅
├── 08.md ✅
└── 09.md ✅
- ✅ 高优先级文件(已包含):README、package.json、配置文件等
- ☑️ 中优先级文件(已包含):代码文件(.py、.js、.ts等)
- ✅ 低优先级文件(已包含):文档、配置等其他文件
- ⏭️ 跳过的文件:被忽略规则排除的文件
- 💾 二进制文件:图片、视频、压缩包等
- 📊 文件过大:超过大小限制的文件
- 🚫 超出限制:超过文件数量限制的文件
本文档包含了 9 个主要文件的内容。
> 对于许多从事数据分析的朋友来说,Jupyter Notebook 是探索和验证想法的利器,但其产物往往是一份混杂着代码、输出和临时笔记的“草稿”。如何将这份草稿转化为一份结构清晰、可维护、可交付的工程产物?本期,我们将见证 AI 在这一转化过程中的关键作用。
欢迎来到吴恩达 Claude Code 笔记第八期。我是手工川。
在前几期的课程中,我们的焦点一直集中在构建和重构传统的 Web 应用上。但 Claude Code 的能力远不止于此。今天,我们将把目光转向一个同样广阔且重要的领域:**数据科学与分析**。
Jupyter Notebook 无疑是数据科学领域的“瑞士军刀”,但它也常常因鼓励线性、杂乱的探索过程而受到诟病。一个“能跑”的 Notebook 和一个“好”的 Notebook 之间,隔着代码组织、关注点分离、可复用性等多重工程鸿沟。
本期课程,我们将直面这一挑战,完成两个层次的跃迁:
1. **从混乱到有序**:利用 Claude Code 将一个典型的、组织混乱的数据分析 Notebook 重构为结构清晰、逻辑与表现分离的模块化代码。
2. **从静态到交互**:在重构的基础上,进一步将 Notebook 的分析结果转化为一个由 Streamlit 驱动的、可交互的 Web 仪表盘(Dashboard)。
### 本期要点 (Key Insights)
1. **Notebook 专属工具**:了解 Claude Code 针对 Jupyter Notebook 的特有工具,如 `read_notebook`,使其能够理解和操作 `.ipynb` 文件的单元格结构。
2. **AI 驱动的重构**:学习如何通过一个详尽的 Prompt,指导 AI 进行“关注点分离”,将数据加载、业务指标计算等逻辑从 Notebook 中剥离,形成独立的 Python 模块。
3. **交互式应用生成**:掌握如何向 Claude Code 清晰地描述一个仪表盘的布局和组件,让它利用 Streamlit 库,将重构后的代码逻辑快速转化为一个 Web 应用。
4. **迭代式开发与调试**:观察在整个重构和生成过程中,如何与 AI 进行多轮对话,修复代码错误、调整应用布局,完成一个真实场景下的迭代开发闭环。
### 手工川笔记
jupyter notebook 是这几年数据分析领域最常用的一款软件(话说我一直好奇大家现在用 lab 比较多,还是 notebook 比较多,想调查一下:)

这个领域还有一本必读书[《利用python进行数据分析》](https://search.douban.com/book/subject_search?search_text=%E5%88%A9%E7%94%A8python%E8%BF%9B%E8%A1%8C%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&cat=1001),教大家如何使用数据分析三大件:numpy、pandas、matplotlib。我当时学的是第二版,现在都已经第三版了(不过译者是我好朋友,欢迎大家多多支持,hhh:)

如果你不想买纸质书的话,也可以访问这里查看[电子版](https://github.com/iamseancheney/python_for_data_analysis_2nd_chinese_version)(当然了,作者还是我的好朋友,欢迎大家多多支持,hhh:)

然后我以为这期视频,Elie老师会带我们如何以jupyter notebook 为核心,接入AI,然后进行微操优化,没想到是直接重构成 **OOP(少年,你知道OOP的四大特性吗?)** 的py代码了,感觉并不是很实用。
因为对于我来说,我往往会把工作流分两部分:
1. 在jupyter notebook里调试
2. 导出单文件代码
3. 重构(可选)
Elie老师只做了2和3,但1可能更需要一些技巧。
另外,在可视化这一块,之前用gradio比较多,Elie用的是streamlit,看起来也不错,学习了!
- gradio-app/gradio(39.6k star): Build and share delightful machine learning apps, all in Python. 🌟 Star to support our work!, https://github.com/gradio-app/gradio
- streamlit/streamlit (41k star): Streamlit — A faster way to build and share data apps., https://github.com/streamlit/streamlit

## 场景复现:一份典型的“混乱”Notebook
课程从一个常见的数据分析场景开始:我们拿到了一份分析电商数据的 Jupyter Notebook。

这份 Notebook 具备了所有“能用但不好用”的典型特征:
* **逻辑混杂**:数据读取、数据清洗、指标计算、图表绘制的代码全部线性地堆叠在一起。
* **代码重复**:为了计算不同的指标,同样的数据处理逻辑可能被复制粘贴了多次。
* **可读性差**:代码块之间缺乏清晰的说明,充斥着临时的变量名和被注释掉的代码。
* **难以复用**:如果想在另一个项目中使用其中的某个计算逻辑,唯一的办法就是“复制粘贴”,这极易引入错误。
* **输出混乱**:虽然最终得出了结论,但过程中伴随着各种警告信息和格式不佳的中间输出。
我们的目标,不是去质疑这份 Notebook 的分析结论,而是要对它的 **工程质量** 进行一次彻底的重构。

## 第一步:从 Notebook 到模块化代码的重构
我们启动 Claude Code,并准备了一个详尽的 Prompt。值得一提的是,为了处理复杂的指令,一个很好的实践是先将 Prompt 写在一个 Markdown 文件中,这样便于组织思路和反复修改。

这个 Prompt 的核心是向 Claude Code 传达了 **“关注点分离” (Separation of Concerns)** 的思想。
```ad-tip {TITLE: "关注点分离 (SoC)"}
关注点分离是软件工程中的一个核心设计原则。它主张将一个复杂的计算机程序分解成多个不同的部分,每个部分只处理一个独立的“关注点”或“职责”。
在本次案例中,我们将原始 Notebook 中混杂的逻辑分离为三个独立的关注点:
1. **数据加载/处理** (`data_loader.py`)
2. **业务指标计算** (`metrics_calculator.py`)
3. **数据展示/可视化** (重构后的 Notebook)
这样做的好处是显而易见的:每个模块职责单一,易于理解、测试和复用。我们的 Prompt 明确要求 Claude Code:
- 创建
data_loader.py:用于封装所有从 CSV 文件读取和预处理数据的逻辑。 - 创建
metrics_calculator.py:用于封装所有业务指标(如年同比增长率、平均订单价值)的计算逻辑。 - 重构 Notebook:创建一个新的、整洁的 Notebook,它不再包含具体的实现逻辑,而是通过导入和调用上述两个模块来完成分析和可视化。
- 提升代码质量:要求为新生成的函数添加文档字符串(docstrings),并改进可视化的美观度。
- 生成辅助文件:创建
requirements.txt和README.md,完善项目的工程化。
Claude Code 接收指令后,开始执行。它使用了 read_notebook 工具来解析原始 .ipynb 文件,然后按计划创建了新的 Python 文件和重构后的 Notebook。

在重构过程中,我们遇到了一个 KeyError。这提供了一个很好的机会来展示人机协作调试的流程:我们将错误信息和相关的代码单元格反馈给 Claude Code,它迅速定位问题并进行了修复。

最终,我们得到了一套结构清晰的代码。新的 Notebook 变得非常整洁,主要由导入语句、高层函数调用和精美的图表组成,可读性和可维护性得到了质的飞跃。
重构后的代码为我们进行下一步的“产品化”打下了坚实的基础。我们的新目标是:将这些分析结果从一个静态的 Notebook,转变为一个可交互的 Web 仪表盘。我们选择了 Streamlit 这个强大的工具。
Streamlit 是一个开源的 Python 库,它能让你用纯 Python 脚本,以极快的速度为你的数据科学和机器学习项目创建美观、可交互的 Web 应用。你无需任何前端知识(HTML/CSS/JS),只需调用 Streamlit 提供的 API,就能生成滑块、按钮、图表等各种 UI 组件,非常适合快速原型设计和数据产品交付。
我们再次采用编写 Markdown Prompt 的方式,向 Claude Code 描述了我们想要的仪表盘的具体 布局:
- Header:包含标题和年份过滤器。
- KPIs:用卡片形式展示四个关键指标(总收入、增长率、平均订单价值、总订单数)。
- Charts:分行展示四个核心图表(收入趋势、品类表现、各州收入地图、客户满意度)。

这种 “布局即 Prompt” 的方法非常高效。我们不是让 AI 自由发挥,而是给了它一个清晰的“线框图”,这大大减少了后续反复调整的成本。
Claude Code 接收到这个新的 Prompt 后,开始编写 dashboard.py 文件。它导入了 streamlit 库,并调用了我们之前重构好的 data_loader 和 metrics_calculator 模块。
在本地运行 streamlit run dashboard.py 后,我们的仪表盘原型诞生了。初版虽然大体可用,但存在一些瑕疵:一些卡片是空的,且默认年份不是我们期望的 2023 年。
我们再次通过一个简短的 Prompt 迭代:make the default year 2023, add filters for months, remove the empty cards。Claude Code 迅速更新了 dashboard.py 代码。
刷新浏览器后,我们得到了一个功能完善、布局合理的交互式仪表盘。在很短的时间内,我们完成了一次从原始数据分析脚本到专业数据产品的端到端转换。

本期的案例,完美地展示了 Claude Code 在数据科学工作流中的应用潜力。它所扮演的角色,远不止一个简单的代码片段生成器。
- 作为“代码架构师”,它帮助我们将混乱的探索性代码,重构为遵循软件工程原则的、模块化的、可维护的代码库。
- 作为“应用开发者”,它根据我们用自然语言描述的布局,快速地将数据分析逻辑封装成一个可交互的 Streamlit Web 应用。
- 作为“敏捷的队友”,它在整个过程中能与我们进行高效的迭代和调试,快速响应我们的调整需求。
这个工作流的转变,让数据科学家和分析师可以将更多的精力投入到更高价值的工作中:定义业务问题、设计分析逻辑、构思产品的最终形态,而将繁琐的代码组织、UI 布局实现等工作,放心地交给 AI 去完成。
在最后一课中,我们将迎来本系列课程的终极项目:从一份 Figma 设计稿出发,从零开始构建一个完整的 Next.js Web 应用。这将是一次对 Claude Code 综合能力的全面检验。
### 09.md
```markdown
> “Design to Code”——这个口号在软件开发领域回响了十余年,无数工具尝试搭建从设计师的创意到工程师代码之间的桥梁,但往往收效甚微。现在,AI Agent 的出现,似乎第一次让我们看到了实现这一梦想的曙GIT。本期,我们将见证 Claude Code 作为这座桥梁的构建者,完成从设计到产品的惊人一跃。
欢迎来到《吴恩达 Claude Code 笔记》的第九期,也是我们课程解读系列的最后一期。我是手工川。
经历了前面八期的学习和实践,我们已经从基础的代码理解、功能开发,一路走到了测试驱动调试、并行开发、乃至云端 GitHub 流程自动化。我们手中的 Claude Code,其形象也从一个“代码补全工具”,逐渐成长为一个能够深度参与软件工程全生命周期的“智能体伙伴”。
今天,我们将迎来本系列课程的终极实战项目,一个足以被称为“毕业设计”的挑战:**完全从零开始,仅依据一份 Figma 设计稿,构建一个功能完备、接入真实数据的 Next.js 全栈应用。**
这不仅仅是一次对 Claude Code 综合能力的全面检验,更是一次对未来 AI 原生开发工作流的深刻预演。
### 本期要点 (Key Insights)
1. **AI 的“眼睛”与“手”**:深入理解 MCP (Model Context Protocol) 服务器的核心价值,看 Claude Code 如何通过连接 Figma MCP Server“看见”设计稿,并通过连接 Playwright MCP Server“验证”自己的开发成果。
2. **两阶段开发范式**:掌握从“视觉复刻”到“功能实现”的两步走开发流程。第一步,AI 专注于将设计稿转化为高质量的前端组件代码;第二步,AI 通过自主研究 API 文档,为静态页面注入真实的数据灵魂。
3. **开发者的角色演变**:在本工作流中,开发者不再是代码的编写者,而是需求的定义者、工具链的配置者、以及 AI 工作成果的验收者,真正成为一名“AI 开发工作流的架构师”。
4. **全链路能力整合**:本次实战是前序所有课程知识的集大成者,综合运用了 Agentic 规划、工具使用(Tool Use)、Web 搜索、文件操作等多种核心能力。
### 手工川笔记
“Design to Code”的承诺,我听了不下十年。从早期的 Photoshop 插件,到后来的 Sketch、Zeplin、Avocode,再到 Figma 自己的代码生成功能,每一代工具都在努力缩短设计与开发之间的距离。但它们大多停留在“样式翻译”的层面——将设计元素的 CSS 属性提取出来,生成的代码往往缺乏结构性、可维护性差,离真正的生产代码相去甚远。
本期课程所展示的工作流,我认为代表了一种根本性的范式转变。AI Agent 的介入,让“Design to Code”**从“翻译”升级为了“理解与创造”**。
这背后的关键,正是 **MCP (Model Context Protocol)**。如果说 Claude Code 是一个聪明的大脑,那么 MCP 就是为这个大脑接上了“感官”和“四肢”的神经接口。通过 Figma MCP,它获得了“视觉”,能够理解设计稿的布局、组件和设计语言;通过 Playwright MCP,它获得了与浏览器“交互”的能力,可以像人一样打开页面、截图、验证 UI。
当一个 AI 同时拥有了“视觉”、“交互能力”和强大的“代码生成逻辑”,它就不再是一个被动的翻译器了。它成为了一个能够**看懂需求、动手实现、并自行检验**的初级前端工程师。而我们,则成为了它的“产品经理”和“技术总监”。这,就是未来。
## 环境搭建与“感官”连接
我们的终极项目,目标是复刻一个展示美国联邦储备经济数据(FRED)的仪表盘。起点,只有一份 Figma 设计稿。

### 项目初始化
我们首先在本地创建一个空的 Next.js 项目,这将是我们应用的基础骨架。
```bash
npx create-next-app@latest .

接下来是至关重要的一步:为 Claude Code 接上“眼睛”和“手”。
-
连接 Figma (眼睛):课程中介绍了两种连接方式。
- Figma 官方 MCP Server:需要在 Figma 桌面应用的偏好设置中启用
Enable Dev Mode MCP Server。这需要在付费的 Pro 计划及以上才能使用。 - Framelink MCP Server:一个优秀的第三方免费替代方案,通过 Figma API Key 进行连接。
我们在终端中使用
claude mcp add命令,将 Figma MCP Server 添加到 Claude Code 的工具集中。 - Figma 官方 MCP Server:需要在 Figma 桌面应用的偏好设置中启用
-
连接 Playwright (手/验证工具):我们同样使用
claude mcp add命令,添加 Playwright MCP Server。

配置完成后,我们可以在 Claude Code 中使用 /mcp 命令,检查两个服务器是否都已成功连接。
环境就绪,大戏开场。我们向 Claude Code 发出了第一个核心指令。

这个 Prompt 的指令链条非常清晰:
- 输入源:提供从 Figma 中复制的设计稿图层链接。
- 分析工具:明确要求使用
figma dev MCP server来分析它。 - 技术栈:指定在 Next.js 应用中,使用
recharts库来创建图表。 - 验证工具:要求使用
playwright MCP server来检查最终成果与设计稿的相似度。
为了应对这个复杂的任务,课程中建议将模型切换到能力更强的 Opus。
Claude Code 接收指令后,它的 Agentic 工作流启动了:
- 调用 Figma MCP:使用
Get_image和Get_Code工具,“看懂”了设计稿的视觉样式和基础代码。 - 代码实现:在 Next.js 的
app/目录下,开始创建符合 React 规范的、组件化的页面代码。 - 调用 Playwright MCP:在初步完成后,它启动 Playwright,打开
localhost:3000,截取一张当前页面的快照,用于和原始设计稿进行对比。
片刻之后,我们看到了初步的成果。令人印象深刻的是,AI 生成的页面不仅在布局和样式上高度还原了设计稿,甚至在一些细节上(如柱状图的渐变效果)比原始设计稿还要精致一些。

一个漂亮的“空壳”已经完成,接下来是注入灵魂——真实数据。我们向 Claude Code 发出了第二个指令:
populate these charts with real-world data from FRED
这个看似简单的指令,触发了一系列复杂的、真正体现 AI Agent 智能的行为:
- 自主研究:Claude Code 首先使用
WebSearch工具,去搜索“FRED API”,找到了官方文档。 - 识别依赖:通过阅读文档,它意识到调用该 API 需要一个 API Key。
- 请求输入:它暂停了任务,并向我们(用户)请求提供 FRED API Key。
- 编写服务:在我们提供了 Key 之后,它编写了一个新的
services/fredApi.js文件,封装了所有与 FRED API 交互的数据请求逻辑。 - 连接前后端:它修改了之前的 React 组件,用
useEffect和useState等 React Hooks,在组件加载时调用 API 服务,获取真实数据,并更新图表状态。

这个过程完美地模拟了一个人类工程师的工作流程:接到需求 -> 查阅资料 -> 发现前置条件 -> 请求资源 -> 编写代码 -> 集成调试。

最终,我们刷新浏览器,仪表盘上显示的不再是静态的占位符,而是来自美国联邦储备数据库的、实时更新的经济指标。在短短几分钟内,我们从一份静态的设计图,得到了一个美观、交互式且由真实数据驱动的全栈 Web 应用。
随着这个终极项目的完成,我们对吴恩达与 Anthropic 这门课程的解读也走到了尾声。
回顾这九期的旅程,我们不仅仅是学会了如何使用一个新工具,更是亲身经历了一次开发思想的变革。我们从最基础的文件操作开始,逐步掌握了测试驱动、并行开发、GitHub 协作、Notebook 重构,直到今天,我们亲手“导演”了一出从设计创意到软件产品的全流程 AI 大戏。
课程的总结言简意赅,却道出了与 Agentic AI 协作的精髓:提供清晰的指令,明确的上下文,并指向相关的文件。这背后,是我们开发者角色的转变——从代码的“生产者”,变为 AI 工作流的“编排者”。
AI 编程的时代已经到来,但这并不意味着程序员的黄昏。恰恰相反,它将我们从繁琐、重复的底层实现中解放出来,让我们能更专注于软件的架构、用户的体验和创意的实现。世上无难事,只要有 Claude。
感谢 Elie Schoppik 老师的精彩讲解,也感谢各位读者的一路相伴。虽然课程解读到此结束,但 AI 辅助开发的探索之旅,才刚刚开始。在接下来的文章中,我将脱离课程本身,分享一些我个人在使用 Claude Code 过程中的最佳实践,以及对这一系列搬运工作流的复盘总结,敬请期待。

-
课程项目源码 (Final Project Source Code):
- 本期课程最终完成的 FRED 仪表盘应用,其完整的 Next.js 源代码都可以在这里找到,是学习和参考的绝佳范例。
- https://github.com/https-deeplearning-ai/FRED-dashboard
-
课程官方文件与 Prompt (Official Course Files & Prompts):
- DeepLearning.AI 官方提供的、涵盖本系列所有课程的配套文件、数据和完整的 Prompt 文本。如果你想 1:1 复现课程中的任何一个环节,这里是你的“宝库”。
- https://github.com/https-deeplearning-ai/sc-claude-code-files
-
DeepLearning.AI 课程主页 (DeepLearning.AI Course Homepage):
- 观看原版视频课程,体验 Elie Schoppik 老师的亲自教学。
- https://learn.deeplearning.ai/courses/claude-code-a-highly-agentic-coding-assistant
# 在你的项目目录中执行
npx create-next-app@latest .# 添加 Figma 官方 Dev Mode MCP Server
claude mcp add --transport http figma-dev-mode-mcp-server http://127.0.0.1:3845/mcp
# 添加 Playwright MCP Server
claude mcp add playwright npx @playwright/mcp@latest-
第一阶段:视觉复刻
- 注意:在 Figma 桌面应用中选中目标图层后,按
Cmd + L(Mac) 或Ctrl + L(Windows) 复制图层链接,替换到 Prompt 中。
Using the following figma mockup (在此处粘贴你的 Figma 链接) use the figma dev MCP server to analyze the mockup and build the underlying code in this next.js application. Use the recharts library for creating charts to make this a web application. Check how this application looks using the playwright MCP server and verify it looks as close to the mock as possible. - 注意:在 Figma 桌面应用中选中目标图层后,按
-
第二阶段:数据注入
- 注意:执行此 Prompt 前,请先前往 FRED 官网 申请你自己的 API Key。
populate these charts with real-world data from FRED
如果你的 Figma 账户不是付费的 Professional Plan 或更高版本,无法使用官方的 Dev Mode MCP Server,可以使用由社区提供的 Framelink Figma MCP Server 作为免费替代方案。
- 配置 Framelink MCP Server:
- 注意:将
YOUR-KEY替换为你自己的 Figma API Key。
claude mcp add "Framelink Figma MCP" -- npx -y figma-developer-mcp --figma-api-key=YOUR-KEY --stdio - 注意:将
### 06.md
```markdown
> 这几个月我大量地使用 claude code 开发各种项目,也曾在同一个项目里启动多个 cc 实现不同的需求,经常碰到多个cc在改写文件时互相打架的问题。在学习本教程之前,我一直都是裸开N个cc让它们野蛮生长,而[上周我们的Vibe Seminar](https://mp.weixin.qq.com/s/jlDHxq4cCV-hn-tIS9I5fw)上甚至就这个问题提出了某种**文件锁**机制。
>
> 但事实上,最佳实践是使用 `git worktree`,这是一种为当前工作区创建额外视图的技术,允许我们在同一个目录但不同的git环境里并行开发,最后一起合并。听起来很复杂,**对于新手来说,合并冲突更是一件极其头疼的事情**。但现在,是AI时代,世上无难事,只要有CC。
>
> 本期教程,进阶必看,I mean it。
欢迎来到《吴恩达 x Anthropic:Claude Code 终极教程》的第六期。我是手工川。
在前面的课程中,我们已经体验了 Claude Code 在单个任务流中的强大能力,无论是实现新功能还是进行复杂的代码重构。但真实的开发场景往往更加复杂,我们经常需要同时处理多个不相关的任务:修复一个紧急 Bug、开发一个新功能、优化 CI/CD 流程等等。
传统的线性工作流在这种情况下会显得捉襟见肘。如果我们为每个任务都切换分支,不仅操作繁琐,而且难以在不同任务间快速预览和测试。如果直接在同一个分支上操作,又极易导致代码混乱和相互覆盖。
本期课程,Elie Schoppik 老师将为我们介绍一套旨在解决此问题的工程实践:**通过 Git Worktree 结合 Claude Code 的多会话能力,实现真正的并行开发**。同时,我们还将学习如何创建自定义的斜杠命令 (`/command`),将高频操作封装起来,进一步优化我们的工作流。
### 本期要点 (Key Insights)
1. **自定义命令**:学习在 `.claude/commands/` 目录下创建自定义的 Markdown 命令,通过 `$ARGUMENTS` 变量接收参数,实现工作流自动化。
2. **Git Worktree 的核心价值**:理解 `git worktree` 如何允许我们在同一个仓库中同时检出多个工作目录,为并行开发提供物理隔离,从根本上避免文件覆盖问题。
3. **并行开发工作流**:掌握从创建 Worktree、在隔离环境中运行独立的 Claude Code 会话,到最终合并成果的完整流程。
4. **AI 辅助解决合并冲突**:观察 Claude Code 如何在合并不同 Worktree 的代码时,自动分析并解决冲突,展示其在处理复杂 Git 操作时的能力。
## 提升效率的第一步:自定义斜杠命令
在深入并行开发之前,课程首先介绍了一个非常实用的功能:创建自定义斜杠命令。
我们已经熟悉了 `/ask`, `/edit` 等内置命令。Claude Code 允许我们通过在项目根目录下的 `.claude/commands/` 文件夹中创建 Markdown 文件来定义自己的命令。文件名即命令名。
例如,为了封装一个“实现前端功能”的流程,我们可以创建一个 `implement-feature.md` 文件:

这个命令文件的内容是一个 Prompt 模板,其中有几个关键点:
- `$ARGUMENTS`:这是一个特殊的变量,它会捕获用户在命令后输入的所有文本。例如,当用户输入 `/implement-feature 添加一个主题切换按钮` 时,`$ARGUMENTS` 的值就是 `添加一个主题切换按钮`。
- **指令约束**:我们可以加入明确的指令,比如 `IMPORTANT: Only do this for front-end features`,来约束 AI 的行为。
- **自动化流程**:可以定义一系列固定的操作,比如 `write the changes you made to file called frontend-changes.md`,将重复性工作自动化。
```ad-tip {TITLE: "自定义命令 vs. CLAUDE.md"}
`CLAUDE.md` 文件中的内容会在 **每次** 启动 Claude Code 会话时自动加载到上下文中,它适合存放项目级的、全局性的背景信息和高频指令。
而 `.claude/commands/` 中的自定义命令则 **不会** 自动加载。它们只有在被用户显式调用时才会生效。这种设计非常适合封装那些非全局、特定场景下才会使用的工作流。
课程中,Elie 老师还演示了一个常见操作:让 Claude Code 自行提交代码变更。

这个 add and commit changes made 的 Prompt 确实很实用。我的思考是,对于像 commit 这样高频且有固定规范的操作,将其封装成一个强大的自定义命令会是更好的选择。这让我想起了我去年花了不少时间打磨的一个自动化 commit 工具 oh-my-commit,它支持 Conventional Commits 规范,并提供了 VS Code 插件。虽然现在基于 Claude Code 的无界面开发模式越来越主流,但我认为一个好的 commit 系统,尤其是在与 CI/CD 集成时,价值依旧。因此,我基于课程的启发,设计了一个更完备的 /git-add-commit 命令(详见文末附录),它能自动分析代码变更、遵循 Conventional Commits 风格并生成中文信息。
此外,为了避免每次执行 git 等命令时都弹出授权确认,我们可以在 .claude/settings.local.json 文件中配置命令白名单,实现真正的自动化。

现在,我们来解决核心问题:如何同时在同一个代码库上安全地进行多项开发任务?
直接打开多个终端窗口,在同一个分支上运行多个 Claude Code 实例,几乎必然会导致灾难。当两个实例试图修改同一个文件时,后保存的会覆盖先保存的,造成代码丢失和逻辑混乱。
Git 提供了完美的解决方案:worktree。
`git worktree` 是一个 Git 命令,它允许你将仓库的多个分支同时检出到文件系统上的不同目录中。每个目录都是一个独立的、功能齐全的工作区,拥有自己的工作文件、暂存区和分支状态,但它们共享同一个底层的 `.git` 数据库。
这与 `git clone` 不同。`clone` 会创建一个全新的、独立的仓库副本。而 `worktree` 只是创建了多个“视图”或“工作台”,它们都指向同一个中央仓库。这使得它非常轻量,且便于在不同任务之间共享提交和对象。

课程中,我们通过以下步骤建立了并行开发环境:
-
创建 Worktree 目录:首先,创建一个用于存放所有 Worktree 的文件夹,例如
.trees,并将其加入.gitignore。 -
添加 Worktree:针对每一项开发任务,使用
git worktree add命令创建一个新的工作目录。每个 Worktree 都会自动基于main分支创建一个同名的新分支。# 任务1: UI 功能开发 $ git worktree add .trees/ui_feature # 任务2: 测试框架增强 $ git worktree add .trees/testing_feature # 任务3: 代码质量工具集成 $ git worktree add .trees/quality_feature
执行后,我们的项目结构会如下图所示:

现在我们有了三个物理隔离但共享 Git 历史的工作区。接下来,我们为每个 Worktree 目录打开一个独立的终端窗口,并分别启动 Claude Code 会话。
我们在三个并行的会话中,分别给 Claude Code 分配了不同的任务:
- UI Feature (位于
.trees/ui_feature):- 任务:使用我们刚创建的
/implement-feature命令,添加一个亮色/暗色主题切换按钮。 - Prompt:
/implement-feature Toggle Button Design - Create a toggle button...
- 任务:使用我们刚创建的
- Testing Feature (位于
.trees/testing_feature):- 任务:增强现有的测试框架,为 FastAPI 端点添加 API 测试。
- Prompt:
Enhance the existing testing framework for the RAG system...
- Quality Feature (位于
.trees/quality_feature):- 任务:集成
black代码格式化工具,并创建运行质量检查的脚本。 - Prompt:
Add essential code quality tools to the development workflow...
- 任务:集成

我观察到一个细节:Elie 老师只在第一个 UI 任务中使用了自定义的 /implement-feature 命令。这可能是因为后两个任务更多是工程配置而非狭义的“功能”开发。
这三个 Claude Code 实例开始并行工作。它们各自修改文件、安装依赖。值得注意的是,任务 2(测试)和任务 3(代码质量)都需要修改 pyproject.toml 这个配置文件。由于它们在不同的 Worktree 中操作,因此不会发生实时覆盖。这个潜在的冲突被推迟到了最后的合并阶段。
当所有任务在各自的 Worktree 中完成后,我们为每个 Worktree 的变更分别创建了 commit。
# 在 .trees/ui_feature 终端中
claude> add and commit with a descriptive message
# 在 .trees/testing_feature 终端中
claude> add and commit with a descriptive message
# 在 .trees/quality_feature 终端中
claude> add and commit with a descriptive message现在,我们关闭这三个终端,回到主工作目录的终端,准备将所有成果合并到 main 分支。
我向 Claude Code 发出了一个总括性的指令,让它负责整个合并过程,并处理可能出现的任何冲突。

Claude Code 开始按顺序合并 ui_feature、testing_feature 和 quality_feature 分支。前两个合并很顺利。当合并 quality_feature 时,预期的冲突发生了——因为 main 分支(已经合并了 testing_feature 的变更)和 quality_feature 分支都修改了 pyproject.toml 文件。
此时,Claude Code 展现了它处理复杂工作流的能力。它检测到了合并冲突,并自动进入冲突解决模式。

它分析了 pyproject.toml 文件中的冲突标记,理解了双方的修改意图(一方添加了 pytest 配置,另一方添加了 black 配置),然后智能地将两部分配置合并到了一起,生成了一个正确的、无冲突的文件版本。最后,它自动完成了合并提交。
这个过程相当流畅。对于开发者来说,处理合并冲突,尤其是配置文件中的冲突,是一项繁琐且容易出错的任务。Claude Code 在这里的表现证明,AI 可以在版本控制的复杂环节中扮演可靠的助手角色。

最终,我们在浏览器中验证,主题切换功能已经成功实现。至此,三项并行的开发任务全部完成并整合到了主分支中。

本期课程的核心,是向我们展示了一套现代、高效的并行开发工作流。它并非由单一的某个工具构成,而是 Claude Code 的多会话能力 与 Git Worktree 的隔离机制 精妙结合的产物。
这个工作流的价值在于:
- 提升吞吐量:它让我们能够同时启动和推进多个开发任务,极大地缩短了项目的总体交付周期。
- 保证安全性:通过 Worktree 提供的物理隔离,彻底杜绝了并行开发中因文件覆盖导致的代码丢失风险。
- 降低心智负担:将繁琐的 Git 操作(如合并、解决冲突)和重复性任务(如功能实现模板、提交信息生成)委托给 AI,使开发者能更专注于创造性的核心工作。
我们从中看到,AI 编程助理的演进方向,不仅仅是提升代码生成本身的质量,更在于深度融入并优化整个软件开发的工程实践。它正在从一个“结对编程的伙伴”演变为一个“开发流程的调度器与优化器”。
在下一课中,我们将把视野从本地终端扩展到云端,探索 Claude Code 如何与 GitHub 集成,以实现 PR review 等协作流程的自动化。
这是我用于生成标准格式自定义命令的“元命令”,可以确保所有命令都遵循统一的结构和版本规范。
---
allowed-tools: Write(*), Read(*), Edit(*), Append(*), Bash(ls:*), Bash(date:*)
description: Generate optimized slash commands
version: "3.3.0"
author: "公众号:手工川"
---
# Meta Command
Create slash commands using two-file architecture.
## Files to Generate
For command `XX`:
- **XX.md** - Command file
- **XX.changelog** - Version history
## Arguments Format
`<name> "<description>" [project|user] [requirements]`
## Process
1. Check if command exists:
ls ~/.claude/commands/XX.md
2. Generate **XX.md**:
***
allowed-tools: [required tools]
description: one-line description
version: "1.0.0"
author: "公众号:手工川"
***
# Command logic
3. Generate **XX.changelog**:
# Changelog for XX
## v1.0.0 - YYYY-MM-DD
- Initial version
Author: 公众号:手工川
Created: YYYY-MM-DD
## Design Principles
- Generated content should display correctly in various environments
- Use universally compatible formats for code examples
## Version Rules
- New: v1.0.0
- Patch: Bug fixes (1.0.1)
- Minor: Features (1.1.0)
- Major: Breaking (2.0.0)
## Tool Selection
- Git: `Bash(git:*)`
- GitHub: `Bash(gh:*)`
- Files: `Read(*)`, `Write(*)`, `Edit(*)`
- Search: `Glob(*)`, `Grep(*)`
- Web: `WebFetch(*)`, `WebSearch(*)`
Execute: `/meta-command <name> "<desc>" [options]`基于课程启发,我设计的更强大的 git-add-commit 命令,支持 Conventional Commits 规范和中文消息。
---
allowed-tools: [Bash(git:*), Read(*), Grep(*), LS(*)]
description: Add and commit with conventional style
version: "1.0.1"
author: "公众号:手工川"
---
# Intelligent Git Commit Command
You are creating a git commit with the following features:
- **Default language**: Chinese (中文) for commit messages
- **Conventional Commit style**: Use conventional commit format (type(scope): description)
- **User context integration**: Accept and incorporate user-provided additional context
## Configuration Settings
default_language: "zh-CN"
commit_style: "conventional"
types:
- feat: 新功能
- fix: 修复bug
- docs: 文档更新
- style: 代码格式调整
- refactor: 重构
- perf: 性能优化
- test: 测试相关
- build: 构建系统
- ci: CI/CD配置
- chore: 其他更改
- revert: 回滚提交
## Workflow
1. **Analyze current changes**:
- Run `git status` to check for uncommitted changes
- Run `git diff --cached` to see staged changes
- Run `git diff` to see unstaged changes
- Identify the main type of changes and affected scope
2. **Parse user input**:
- Check if user provided additional context or specific requirements
- Extract any specific commit type or scope preferences
- Consider any attention points mentioned by the user
3. **Generate commit message**:
- Use conventional commit format: `<type>(<scope>): <description>`
- Write description in Chinese by default
- Incorporate user's additional context if provided
- Keep the subject line under 50 characters
- Add detailed body if needed (wrapped at 72 characters)
4. **Stage and commit**:
- Ask user to confirm which files to stage (if not already staged)
- Create the commit with the generated message
- Show the commit result to the user
## Example Usage
When the user runs `/git-add-commit`, you should:
1. First check the git status and changes
2. Analyze what type of changes were made
3. Generate an appropriate conventional commit message in Chinese
4. If the user provided additional context like "注意性能优化部分", incorporate it
5. Create the commit
## Important Notes
- Always analyze the TARGET directory where the command is run
- Do NOT assume anything about the current directory structure
- Support both staged and unstaged changes
- Allow user to override language or commit style if specified
- Ensure commit messages are meaningful and descriptive
## User Input Parameters
The user can provide additional context in several ways:
- Direct description: Additional text after `/git-add-commit`
- Type override: Specify a different commit type
- Language override: Request English or other language
- Scope specification: Define a specific scope for the commit
Generate appropriate conventional commit messages based on the actual changes in the target repository.今天学习的本期教程对我启发很大,我本来想把这样并行开发的特性集成到自己开源的ccm上,结果社群里的朋友直接推荐了一款已经实现的 C 端产品 Conductor 。

我赶紧试了试,发现确实可以,以下是一些评测经历(没有收钱,也感兴趣创始团队,欢迎介绍)。




简单体验了一下各个功能,我觉得产品设计还是挺棒的,它:
- 场景明确、定义良好、界面清爽
- 支持多项目(在 sidebar 里一条条可切换)
- 每个项目支持多个 space(基于 git worktree 所以不会互相干扰)
- 支持快捷选择三种思考模式(尽管官方最佳实践有四种)
我个人对这样的产品是有需求的,但和我目前的开发习惯还有些差异:
- 我现在是在 iterm 里通过 tmux 去管理项目的,不太想去使用一个额外的 GUI(如果要用的话,我会更 prefer VSCode)
- 在 iterm 里,我是切分多列,每一列一个项目,这样允许我同时看所有项目的开发情况,而非 Conductor 里每个 workspace 占满整个软件,不同 workspace 以及不同 project 得相互切换
- 不过以上我不觉得是 Conductor 的问题,只是我的用户习惯不一样,可能对于我这样的“超级”开发者希望有更多的全局感:)

所以,总之,Conductor 还是不错的,推荐大家可以下载安装使用,目前仅支持 mac,以及 proxy 代理感觉要好好弄一下:)
### 02.md
```markdown
# 吴恩达 Claude Code 教程 02:揭秘 AI 编程助理的核心机制
欢迎回到由我们(手工川)为大家搬运并解读的 DeepLearning.AI 与 Anthropic 官方合作课程——**Claude Code: A Highly Agentic Coding Assistant**。
在 [上一期](https://mp.weixin.qq.com/s/wcAOpNHjngxyXdg2NV2kQg) 中,我们对课程进行了总体介绍。今天,我们将跟随 Anthropic 的 Elie Schoppik,深入探讨 Claude Code 的核心工作理念,并亲手完成第一个由 AI 构建的可视化项目。

## 什么是智能体化编程助理?
当我们谈论 **“智能体系统” (Agentic Systems)** 时,我们实际上是在讨论一个由 **模型 (Model)**、**工具集 (Tools)** 和 **执行环境 (Environment)** 协同工作的系统。
传统的语言模型擅长处理输入和输出,但它们本身并不了解你的代码库结构,也不知道如何查找文件或处理复杂的多步骤任务。

Claude Code 的解决之道,是为大模型提供一个轻量级的 **“约束框架” (Harness)**。通过这个框架,我们能够充分利用模型的智能,在命令行中执行复杂的编码任务。模型不再是被动地回答问题,而是主动地 **规划、获取数据、并采取行动**。

在这个系统中:
* **模型**:是智能的核心,你可以根据任务复杂度和订阅类型选择 **Opus** 或 **Sonnet** 模型。
* **环境**:为模型提供了行动的场所,使其能够明确需要哪些数据,制定计划,然后执行。
* **工具与记忆**:则是我们接下来要深入探讨的关键组件,它们赋予了模型超凡的能力。
## Claude Code 的核心能力
许多人可能认为 AI 编程工具的主要用途就是编写大量代码。然而,Claude Code 最强大的功能之一,是从代码的 **发现、解释和设计** 开始的。

在你开始用它编写代码之前,不妨先用它来快速熟悉一个陌生的代码库。它的能力远不止于此,涵盖了:
* **代码编写**
* **代码重构**
* **错误调试**
* **数据分析与可视化**
* **与 GitHub 等环境集成**
## 环境准备:安装与配置
在深入实践之前,请根据以下步骤完成 Claude Code 的安装。
### 安装 Claude Code
1. **安装 [Node.js](https://nodejs.org/en/download)**:首先确保你的系统中已安装 Node.js 环境。
2. **全局安装 Claude Code**:打开终端,运行以下命令:
```bash
npm install -g @anthropic-ai/claude-code
```
* **温馨提示**: 国内用户在通过 `npm` 安装时,可能会遇到网络连接问题。请确保您的网络环境能够正常访问相关资源,或自行配置网络代理以完成安装。更多安装指南,请参考 [官方文档](https://docs.anthropic.com/en/docs/claude-code/setup),Windows 用户请特别关注 [Windows 安装部分](https://docs.anthropic.com/en/docs/claude-code/setup#windows-setup)。
3. **启动 Claude Code**:
* **方式一 (独立终端)**:导航到你的项目文件夹,然后输入 `claude` 命令。
* **方式二 (VS Code 集成)**:在 VS Code 的集成终端中输入 `claude`,相关插件将会被自动安装。如果遇到问题,请确保 `code` 命令已添加到系统 PATH 中。
### 使用成本
要体验课程中的所有功能,你可以选择以下任一方式:
* **订阅套餐**:你可以订阅 [Pro 或 Max 套餐](https://www.anthropic.com/claude-code#:~:text=Pro,Sign%20up)。完成本系列课程的学习,Pro 套餐已足够。
* **API 按量计费**:你也可以根据 API 的使用量付费。在任何会话中,你都可以使用 `/cost` 命令来查看当前会话所产生的费用。
## 核心组件剖析:工具、搜索与记忆
### 工具使用 (Tool Use) - 赋予模型行动力
想象一下,你问模型:“某个文件里写了什么代码?” 模型本身无法浏览你的文件系统。**“工具使用”** 机制正是为了解决这个问题。

Claude Code 内置了一套精简而强大的工具集,赋予了模型与本地环境交互的能力。

这些工具包括:
* **文件读写与编辑**
* **代码模式匹配与搜索**
* **网络搜索**
* **执行 Shell 命令**
* **创建和运行子智能体** 来处理更具挑战性的任务
正是这些工具,让 Claude Code 从一个简单的问答助手,转变为一个能够自主收集信息、解决复杂问题的智能体。

此外,Claude Code 是 **高度可扩展的**。你可以通过连接到 **MCP (Model Context Protocol) 服务器** 来为其添加更多工具。MCP 是一种开源的、模型无关的协议,允许 AI 系统与外部数据和工具轻松通信。在后续课程中,我们将学习如何利用它连接 Figma 等服务。

### 智能体搜索 (Agentic Search) - 安全的本地化探索
与某些需要索引整个代码库并上传到云端的工具不同,Claude Code 采用了一种名为 **“智能体搜索” (Agentic Search)** 的技术。

它不会为你的代码库创建结构化的表示或嵌入索引。相反,它利用其智能体和工具集,在需要时 **主动地** 在你的本地文件系统中查找信息。这种方法的巨大优势在于:
* **安全性高**:你的代码永远不会离开本地环境。
* **上下文精准**:避免了将整个代码库作为上下文的低效做法。
### `CLAUDE.md` - 跨会话的持久化记忆
Claude Code 如何记住你在不同会话中的偏好和项目背景?答案是 `claude.md` 文件。

当你启动 Claude Code 时,它会自动在你的项目中寻找并加载这个 Markdown 文件。你可以将它当作一个 **项目工作笔记**,在其中定义:
* **通用配置**
* **代码风格指南**
* **项目依赖说明**
* **常用命令**
这样,Claude Code 在每次启动时都能快速进入状态,如同一个已经熟悉你项目的团队成员。所有的对话历史也都存储在本地,你可以随时清除或恢复。
## 实战演练:你的第一个 AI 程序诞生了
理论讲解之后,让我们通过一个简单的实例,直观感受 Claude Code 的工作流程。
**目标**:在一个空目录下,让 Claude Code 为我们创建一个有趣的网页可视化效果。
**第一步:启动 Claude Code**
在 VS Code 的终端中,我们进入一个空文件夹 `demo`,然后输入 `claude` 命令启动工具。
```bash
claude

第二步:下达指令 我们给出一个非常简单的指令:“为我创建一个很酷的可视化效果。”
> Make a cool visualization for me.
Claude Code 会立即开始思考并制定一个 待办事项列表 (To-do list)。它会规划创建 HTML、CSS 和 JavaScript 文件来实现这个目标。
第三步:AI 自动编码与文件修改 由于我们是在 VS Code 中操作,Claude Code 的集成功能会让我们清晰地看到它正在进行的文件创建和修改。

我们可以接受这些更改,并授权它在后续步骤中自动执行,无需每次都请求许可。
第四步:运行与查看结果 编码完成后,我们甚至可以直接让 Claude Code 帮我们打开浏览器来查看结果。
> Open it in the browser for me.
它会确认将要执行的命令,然后启动浏览器。

瞧!一个带有粒子效果、可以交互的网页就这样诞生了。我们可以随时要求 Claude Code 对其进行修改、扩展功能,整个过程无缝且高效。
为了方便你跟随课程进行实践,这里是课程中涉及到的所有代码库和文件的链接:
- RAG 聊天机器人项目 (课程 2-6)
- 电商数据分析项目 (课程 7)
- Figma 设计稿转 Web 应用项目 (课程 8)
- 课程中使用的 Prompt 及总结
- 你可以在这个 代码库 中找到课程所有章节使用的 Prompt 提示词和功能总结。
本期内容深入剖析了 Claude Code 作为智能体系统的核心机制:它如何通过工具与环境交互,如何通过智能体搜索安全地理解代码,以及如何通过 CLAUDE.md 文件维持记忆。最后的实战演练更是直观地展示了其强大的自动化编码能力。
从一个简单的想法到一个可运行的程序,Claude Code 展现了新一代 AI 编程助理的巨大潜力。
在下一期中,我们将更进一步,学习如何在一个更大型、更复杂的现有代码库中使用 Claude Code。敬请期待!
### 03.md
```markdown
欢迎来到吴恩达与 Anthropic 官方合作课程的第三期。在 [上一期](https://mp.weixin.qq.com/s/WsgTjgruDgm9wNwx7stbww) 中,我们体验了 Claude Code 从零到一的创造力,并完成了环境配置。
今天,我们将进入一个更真实的开发场景:接手一个已有的、功能复杂的 RAG (检索增强生成) 聊天机器人项目。我们将学习如何利用 Claude Code 快速理解代码库、梳理复杂逻辑,并为其构建一套持久化的“记忆”——`CLAUDE.md` 文件系统。
> 手工川注:
> 1. 本文我们基于官方文档对视频内容中的 CLAUDE.md 做了更加全面的讲解
> 2. 个人也推荐大家可以使用 ascii 去画原型,参考:[和 Claude Code 讨论产品的界面和交互设计](https://mp.weixin.qq.com/s/uyYPvqLPTmu4UKbALQKOPw)
> 3. 上下文管理其实是个慢工细活,它核心的议题是“”

## 项目实战:与 RAG 聊天机器人代码库的初次对话
我们面临的项目是一个能与 DeepLearning.AI 课程资料对话的 RAG 聊天机器人。在不了解任何代码细节的情况下,我们的首要任务是快速建立对项目整体的认知。
### 从高层问题入手
我们无需逐个文件阅读,而是直接向 Claude Code 提出一个高层次的问题,例如:
> "Give me an overview of the codebase."
> (给我一份代码库的概述。)
Claude Code 会立即启动它的 **“智能体搜索” (Agentic Search)** 机制,智能地识别出项目中的关键文件,并为我们提炼出一份包含 **项目架构、关键组件、主要功能** 的摘要。

我们可以进一步追问,比如深入了解 RAG 的实现细节:
> "How are these documents processed?"
> (这些文档是如何被处理的?)
Claude Code 会精准定位到处理文本分块、添加上下文、存储元数据的相关代码,并清晰地解释整个流程。这个过程充分证明了:**Claude Code 不仅是一个出色的工程师,更是一个卓越的解说员**。
## 从文本到图表:让 AI 解释复杂流程
对于一个 Web 应用,理解用户请求从前端到后端的完整链路至关重要。我们可以让 Claude Code 为我们追踪这一流程:
> "Trace the process of handling a user's query from front end to back end."
> (追踪处理用户查询从前端到后端的全过程。)
在执行过程中,Claude Code 会展示一个清晰的 **“待办事项列表”**,让我们了解它的思考路径。它会依次分析前端代码、API 接口、RAG 系统,最终生成一份详尽的步骤分解。
然而,纯文本有时不够直观。我们可以提出一个更有趣的要求:
> "Draw a diagram that illustrates this flow."
> (画一张图表来阐释这个流程。)
Claude Code 会在终端中为我们生成一幅 **ASCII 艺术图表**。这是一种非常实用的方式,无需离开命令行环境,就能对复杂系统流程一目了然。

这幅图清晰地展示了从前端请求、后端处理、向量数据库 (Chroma DB) 检索,到最终由大模型生成响应的全过程。尽管只是字符画,但信息量十足。当然,如果我们有需要,也可以要求它生成用于 Web 的 D3.js 或 Recharts 代码,来创建更丰富的可视化图表。
## 核心机制:构建 Claude 的长期记忆 (`CLAUDE.md`)
到目前为止,我们与 Claude Code 的所有交互都是基于当前会话的。为了让 AI 能够“记住”项目的关键信息和我们的特定偏好,我们需要引入其核心的记忆机制——`CLAUDE.md` 文件系统。
### 初始化项目记忆
我们推荐在接手任何新项目时,首先运行 `/init` 命令。
```bash
> /init
这个命令会自动分析整个代码库,并生成一个初始的 CLAUDE.md 文件。这个文件是 至关重要的,它承载了 Claude Code 在本项目中的长期记忆。

CLAUDE.md 文件系统并非单一文件,而是一个分层的体系,以满足不同范围的需求。理解这个体系对于高效使用 Claude Code 至关重要。
| 记忆类型 | 文件位置 | 目的与用途 | 共享范围 |
|---|---|---|---|
| 企业策略 | 系统级目录 (如 /etc/claude-code/) |
由 IT/DevOps 管理的全公司范围的指令 | 组织内所有用户 |
| 项目记忆 | ./CLAUDE.md |
团队共享的项目特定指令,应提交到版本控制 | 所有项目成员 |
| 用户记忆 | ~/.claude/CLAUDE.md |
适用于你所有项目的个人偏好 | 仅自己 (所有项目) |
| 本地项目记忆 | ./CLAUDE.local.md |
个人在当前项目中的特定偏好 (已被废弃) | 仅自己 (当前项目) |
加载机制:Claude Code 会从当前工作目录开始,向上递归查找 CLAUDE.md 文件,直到根目录。同时,它也会加载全局的用户记忆和企业策略。高层级的记忆会先被加载,形成基础上下文,然后被更具体的低层级记忆覆盖或补充。

重要更新:根据最新文档,原有的 CLAUDE.local.md 文件已被废弃。现在推荐使用 import 语法 在主 CLAUDE.md 文件中引入个人配置文件,例如 @~/.claude/my-project-instructions.md。这种方式对 Git worktrees 的支持更好。
除了编辑文件,我们还可以使用 # 快捷指令在对话中快速添加记忆。例如,我们的项目推荐使用 uv 作为包管理器,为了防止 Claude 使用 pip,我们可以这样指示:
# Always use UV to run the server, do not use pip directly.
手工川注:我们今年的 python 项目也在迁移到 uv 管理。

Claude Code 会询问你希望将这条记忆保存在哪个文件中(项目、本地或用户),选择后,CLAUDE.md 文件就会被自动更新。
Claude Code 还提供了一系列内置命令来提升交互效率。

/help: 显示所有可用命令的帮助信息。/clear: 完全清空当前对话历史,开始一个全新的上下文。/compact: 清空历史,但保留一份摘要,以便在新的对话中延续之前的背景。/ide: 连接到你的 IDE (如 VS Code),让 Claude 知道你当前正在查看或编辑哪个文件。Esc键: 随时中断 Claude 正在执行的任何任务。
一个非常实用的功能是 Claude Code 与 Git 的深度集成。当你完成了一些修改后,不必再手动编写 git add 和 git commit 命令。

你可以直接让 Claude Code 帮你提交更改。它不仅会执行 Git 命令,还会根据本次修改的内容,自动生成一段 高质量、描述性强的 commit message。这对于维护清晰的版本历史和团队协作非常有价值。
本期课程我们完成了从理论到实践的跨越。我们学会了如何利用 Claude Code 探索一个真实、复杂的代码库,通过提问和图表生成快速掌握其核心逻辑。更重要的是,我们深入了解了 CLAUDE.md 这一核心记忆系统,学会了如何通过分层配置和动态更新,将 AI 助理调教成最懂你项目的专家。
掌握了这些基础,我们已经准备好让 Claude Code 真正为我们“动手”了。下一期,我们将开始为这个 RAG 聊天机器人添加全新的功能。敬请期待!
### 07.md
```markdown
> 一个强大的 AI 编程助理,其价值绝不应局限于本地的单机开发。真正的工程实践是协作的、流程化的,发生在像 GitHub 这样的平台上。本期,我们将把 Claude Code 从个人终端的得力助手,提升为融入团队协作流程的自动化“虚拟队友”。
欢迎来到吴恩达 Claude Code 笔记第七期。我是手工川。
上一期,我们通过 `git worktree` 解决了在本地并行开发时多个 Claude Code 实例互相干扰的问题,实现了个人开发效率的飞跃。但这主要还是在优化“单兵作战”的体验。现代软件开发的核心是团队协作,而 GitHub 正是这个协作宇宙的中心。
一个很自然的问题是:我们的 AI 助手,能否走出本地终端,无缝地融入到 Pull Request 审查、Issue 修复这些核心的团队协作环节中去?
本期课程,Elie Schoppik 老师就为我们完整地展示了这幅蓝图。我们将学习如何将 Claude Code 与 GitHub 深度集成,并探索其更高级的定制化能力——Hooks 系统,从而实现从宏观的 CI/CD 流程到微观的工具执行环节的全方位自动化。
### 本期要点 (Key Insights)
1. **GitHub 集成**:学习如何通过 `/install-github-app` 命令,将 Claude Code 作为一款 GitHub App 安装到仓库中,使其具备监听和响应仓库事件的能力。
2. **自动化代码审查 (PR Review)**:了解集成后生成的 GitHub Actions 工作流,如何让 Claude 机器人自动为新的 Pull Request 提供代码分析、质量检查和安全建议。
3. **远程任务指派 (Issue Fixing)**:掌握在 GitHub Issue 中直接 `@claude`,指派它修复 Bug 或实现功能。Claude 会自动分析问题、修改代码、并创建一个新的 PR 来解决该 Issue。
4. **Hooks 系统**:初探 Claude Code 的高级定制功能 Hooks。理解如何通过 `PreToolUse` 和 `PostToolUse` 等钩子,在工具执行前后注入自定义的脚本,实现更精细的工作流自动化。
### 手工川笔记
这一期也有很多惊喜。
作为一名被 github 喂大的男人,说实话,挺惭愧的,对 github 的探索也仅仅牛毛而已。

我印象很深刻的是,前几年我经常使用的一个开源库 wechaty,其技术负责人卓桓兄很早就引入了 ai bot,帮助 review 大家的 issue,后面又引入到了他们的 discord 社区。

这一期,在 Elie 老师的带领下,我们可以看到,原来在自己的 github 仓库上植入一个 ai bot 是这么 so easy 的事,甚至可以让它自动地在云端改代码,怪不得云 IDE 的估值现在真地是水涨船高,程序员真地越来越危,玩法越来越花。
至于第二个 part 的 claude code hooks,这也是一个非常有用的功能,在我们的手工川自研插件 [ccm(claude-code-manager)](https://github.com/markshawn2020/claude-code-manager) 里很早地就支持了 post-tool-use hook,以支持实时的 token 统计。

btw,昨天学完 [第六期(CC + git worktrees)](https://mp.weixin.qq.com/s/_4oPcqy-vcQWcsAOO4DKZA) 教程后,觉得非常有用,所以当天晚上就兴奋地集成到了 ccm 里,大家可以尝试体验。
```ad-note CCM 2.4.1 重磅更新
本版本新增 ccm feat - Git Worktree 管理功能
ccm feat add payment # 创建特性分支
ccm feat list # 交互式选择(可删除)
ccm feat merge # 合并完成的特性
✨ 支持并行开发多个特性,互不干扰
📦 更新:npm update -g claude-code-manager
课程开始,我们首先延续了上一期的工作,做了一些清理。我们之前使用 git worktree 创建了多个工作区,但在合并后忘记了清理。这里我们学习了一个新技巧:使用 claude --resume 命令可以列出并恢复之前的会话,非常方便。

我们让 Claude 清理了 .trees 文件夹和相关的 Git 分支,然后将所有合并后的代码推送到了 GitHub 远程仓库。至此,本地的工作告一段落,我们的舞台正式转向云端。

要让 Claude Code 在 GitHub 上“活”起来,我们需要将其作为一款 GitHub App 安装到我们的仓库中。这个过程通过一条简单的命令即可启动:
/install-github-app
这个命令会引导我们完成一系列的授权流程,包括 GitHub CLI 的认证和 Claude 服务的授权。

安装完成后,最核心的变化是 Claude Code 会在我们的仓库中创建一个 .github/workflows/ 目录,并自动生成两个 GitHub Actions 工作流文件:claude.yml 和 code-review.yml。
GitHub Actions 是 GitHub 提供的持续集成和持续部署(CI/CD)服务。它允许你在 GitHub 仓库中自动化你的软件开发工作流。你可以创建自定义的工作流(Workflows),在仓库发生特定事件(如 `push`, `pull_request`)时,自动执行一系列任务(Jobs),例如构建、测试、打包和部署代码。这些工作流由 YAML 文件定义,存放在 `.github/workflows/` 目录下。
这两个 YAML 文件,实际上就是我们新入职的“AI 队友”的行动指令集:
code-review.yml:定义了当有新的 Pull Request 被创建时,自动触发 Claude Code 进行代码审查的流程。claude.yml:定义了当在 Issue 或 PR 的评论中@claude时,触发 Claude Code 执行任务的流程。
值得注意的是,这些 YAML 文件是完全开放和可定制的。我们可以修改其中的 Prompt,来调整 Claude Code 审查代码时的关注点,或者限定它只对某些作者、某些分支的 PR 进行审查,提供了极高的灵活性。
完成安装并合并了包含这两个工作流文件的 PR 后,我们的 Claude Code 机器人就正式“上岗”了。
为了测试效果,课程演示了合并这个安装 PR 的过程。我们立刻就看到,一个名为 "Claude" 的 GitHub Action 开始运行。

片刻之后,Claude 在 PR 页面留下了它的审查评论。评论内容结构清晰,包括了代码中做得好的地方以及一些潜在的改进建议。
在我看来,将 AI 作为自动化代码审查的第一道关卡,其价值巨大。它不仅能发现人类审查者可能忽略的细节问题,更重要的是,它建立了一个 客观、一致、不知疲倦 的审查标准。这可以极大地减轻团队中真人审查者的负担,让他们能更专注于业务逻辑、架构设计等更高层次的评审。
除了被动地审查 PR,我们还可以主动地给 Claude 分配任务。课程中模拟了一个场景:我们对之前版本中新增的页面 Header 不满意,想要恢复到旧版样式。
我们在 GitHub 上创建了一个 Issue,用自然语言详细描述了需求:
The application has a new header... Let's go back to the old one. Make sure to keep the toggle theme but just make the header look like what it was before...
然后,在评论区,我们像召唤同事一样,简单地 @claude 并说了一句:Claude, can you fix this for me?

这触发了 claude.yml 工作流。在 GitHub Actions 的日志中,我们可以看到一个熟悉的场景:Claude Code 开始了它的思考和规划过程,生成了一个 To-do list,这和我们在本地终端中看到的行为完全一致。

任务完成后,Claude 自动创建了一个新的 Pull Request,其中包含了解决该 Issue 所需的所有代码修改。更有趣的是,这个新 PR 同样触发了 Code Review 流程——Claude 开始审查自己刚刚写的代码。这种“自审”机制,为代码质量提供了又一层保障。

我们将这个 PR 合并,然后回到本地拉取最新的代码。刷新页面后,可以看到 Header 确实已经按要求恢复了旧版样式。整个流程从提出需求到代码合并,完全在 GitHub 上通过人机对话完成,这极大地改变了传统的问题处理工作流。
在课程的最后,Elie 老师介绍了一个更深层次的定制化功能:Hooks(钩子)。

对于熟悉 Git Hooks 或 Webhooks 的开发者来说,这个概念会非常亲切。Hooks 允许我们在 Claude Code 内部生命周期的特定事件点,注入我们自己的代码或命令。
我们可以通过 /hooks 命令打开一个编辑器来管理这些钩子。

Claude Code 提供了多种可用的事件钩子,例如:
PreToolUse:在某个工具即将被执行 之前 触发。PostToolUse:在某个工具执行完成 之后 触发。OnUserSubmit:当用户提交一个新的 Prompt 时触发。BeforeSubagentResponse:在子智能体返回响应之前触发。
为了演示这个功能,课程中创建了一个简单的 PostToolUse 钩子。它的作用是:每当 Read 或 Grep 工具被使用后,就执行一条 say 'All done!' 的 Shell 命令,让电脑语音播报“All done!”。

这个配置会被保存在 .claude/settings.local.json 文件中。
{
"permissions": { ... },
"hooks": {
"PostToolUse": [
{
"matcher": {
"tool_name": {
"$in": ["Read", "Grep"]
}
},
"command": "say 'All done!'"
}
]
}
}虽然 say 命令只是一个有趣的例子,但 Hooks 机制的潜力远不止于此。我们可以利用它来构建非常强大的自动化工作流:
- 自动化测试:创建一个
PostToolUse钩子,匹配Write或Edit工具。每当 AI 修改了代码文件后,自动运行相关的单元测试。 - 代码规范检查:在
PreToolUse钩子中匹配Bash(git: commit),在提交代码前自动运行 Linter 或 Formatter。 - 安全扫描:在
PostToolUse中匹配Bash(npm: install),每当安装了新的依赖后,自动运行npm audit进行安全漏洞扫描。

本期课程的内容,标志着我们对 Claude Code 的使用从“战术层面”进入了“战略层面”。
- GitHub 集成,是在 宏观流程 上实现了自动化。它将 AI 无缝嵌入了团队的 CI/CD 和协作流程中,解决了代码审查、问题修复等流程性、协作性的任务。
- Hooks 系统,则是在 微观执行 上实现了自动化。它允许我们精细地控制 AI 在执行每一个具体工具前后的行为,将我们的个人工作流、项目的特定规范,注入到 AI 的每一次操作中。
将这两者结合,我们实际上是在构建一个高度定制化、全流程自动化的“可编程开发环境”。在这个环境中,AI 不再仅仅是响应我们指令的工具,而是遵循我们预设的规则和流程,主动、可靠地执行任务的系统。开发者作为这个系统的设计者和编排者,其工作效率和对项目质量的把控能力都将得到质的提升。
在下一课,我们将把目光转向数据科学领域,探索 Claude Code 如何与 Jupyter Notebook 结合,进行数据可视化和代码重构。
### 04.md
```markdown
---
title: Claude Code A Highly Agentic Coding Assistant DeepLearning.AI
slug: claude-code-a-highly-agentic-coding-assistant-deep-1755232992543
source: https://learn.deeplearning.ai/courses/claude-code-a-highly-agentic-coding-assistant/lesson/zzhtb/adding-features
datetime: 2025-08-15T04:43:12.543Z
---
## 手工川笔记
本期 Elie 老师(Anthropic在线教育主管)给我们演示了如何使用 claude code(以下简称 cc) 在一个前后端项目上增加新的实现(feature),应该说对很多新手到进阶用户都有一定帮助,以下是结合我个人的一些经验做的笔记。
### 什么样的 prompt 才是好的 prompt
罗列了一下 Elie 老师与ClaudeCode沟通时所使用的prompt:







手工川认为 Vibe Coding 的范式与境界可以划分为如下:
- L1. 我要Z
- L2. 现在是Y,我要Z
- L3. 我做了X,现在是Y,我要Z(X充当Y的补充信息)
- L4. 请基于W,实现Z(直接给出具体步骤 W,而非AI自行推导)
回顾 Elie 老师的 7 条 prompt,基本上都至少满足“我要 Z”,这个Z 具体是什么是一定清晰明确的;而 1、2、6都额外指定了现状是什么;5、6则额外指定了具体的执行路径。
值得注意的是,最长的三条(1、3、7)都是编辑好直接发送的,而且都使用了 markdown 中的无序列表写法,甚至还有分级,大家也可以多多学习这种写法。(尽管手工川很怀疑是不是Elie老师录课的时候prompt一次性没有通过,然后做了一些修改完善:)
另外,`#` 开头的 prompt 表示记忆,Elie 老师自己是边调试边Vibe的,所以不希望AI每次任务结束后自动启用服务,因此在记忆中做了约束;但它同时考虑到其他人可能有不同的习惯,所以建议这种个人偏好放到 `.local` 中去(不被git提交),对团队协作场景来说很有用,值得学习。
### 先计划再编码 vs 先编码再重构
[Claude Code 官方最佳实践(强烈推荐)](https://www.anthropic.com/engineering/claude-code-best-practices) 中提到了十种(之前好像是五种,最近应该是有更新)常见的工作流,其中第一种就是”先设计后编码“,它特别适合你每次**着手一个新的feature/bug修复/重构**时。

顾名思义,先设计后编码并不适用于所有场景,当 AI 已经想清楚的时候,直接让它进入肝活的心流状态往往是更好的,速度更快、token 更省,此外,也有效避免过度思考。AI圈大V宝玉老师也写过一篇相关的博客:[先设计再写代码,还是先实现再重构?AI 编程让这种选择变的简单 | 宝玉的分享](https://baoyu.io/blog/design-code-or-refactor-ai-simplifies),感兴趣可以看看。
我们需要按 `shift + tab`,以在不同模式间进行切换,其中 `Plan Mode` 就是计划模式,它与其他模式的显著区别主要体现在两点:
1. 它会进行更详尽的思考
2. 它是只读的,它会生成一份代码建议,但除非你明确授权,否则不会展开修改计划
也因此,它是**绝对安全**的,并且**生成的代码建议往往是更优**的。

### Thinking Budget & 手工川深度思考指令集
在 Google 的 ai.studio 中,有一个可调节的选项 `thinking budget`,默认 8192,最大可调节为 32768。在我广泛使用 gemini-2.5-pro 进行社交写作时,我往往会直接拉到最高以期待它给我尽可能好的答案,尽管我并未做过详尽的评测。

Claude Code 尽管并未开放给用户调节 thinking budget 的选项,但是在官方最佳实践中,提及了用户可以显式地声明 `think | think hard | think harder | ultrathink` 四种思考模式,它们会迫使 Claude Code 使用更高的思考预算。
但一方面由于我们的沟通习惯是中文,中英混输或者纯中文输入,**实测预期可能不会奏效**,比如对比如下:
- 纯英文输入:`ultrathink how to build a wechat`
- 中英混输:`ultrathink 做一个微信`
- 纯中文输入:`深度思考如何做一个微信`
- ……
知名开发者王巍说“[凡是重复了两次以上的类似prompt,都应该用命令来表述](https://mp.weixin.qq.com/s/p3tk18IPrLPWLScwR6_eWQ)”,我也非常认同,所以在很早的时候,我们手工川也基于自研的 meta command 写了一套深度思考 commands set:
| claude code mode | slash command | shortcut | scenario |
| ---------------- | ------------- | -------- | ----------- |
| normal | - | - | general |
| think | /think | /t | add feat |
| think hard | /think-hard | /tt | bug fix |
| think harder | /think-harder | /ttt | big bug fix |
| ultrathink | /think-ultra | /tttt | refactor |
这样我就可以在 ClaudeCode 里非常方便地输入: `/tttt 做个微信`,轻松实现尽最大努力 PUA ClaudeCode 挑战一个复杂任务的需求。
这些命令真实有效,我们已经在多个开发者社群里收到了有效的反馈意见,例如胡博老师亲测在 think 加持下解决了一个不 think 无法解决的问题:


具体可留言领取。
### 在 Claude Code 中使用文件
在 Claude Code 中输入 `@` 即可引入文件,但有一些细节需要注意。
- 如果文件路径里有空格,需要用引号(最好英文,但中文也可以)包围,否则会找不到。
- 如果文件路径里有一些特殊符号(例如括号),则会导致自动补全部分失效。
例如,在nextjs项目中,我们有时会使用带括号的文件夹代表 [路由组](https://nextjs.org/docs/app/api-reference/file-conventions/route-groups),它的文件组织可能如下:
➜ ~/tmp tree . ├── (dir2) │ ├── file.md │ └── test │ └── file.md ├── dir1 │ ├── file.md │ └── test │ └── file.md └── file.md
5 directories, 5 files
测试结果如下:
| 指令 | 候选结果 | 是否符合预期 |
| ------ | ----------------------- | -------- |
| @file | 全部五个文件 | ✅ |
| @dir | 全部两个文件夹与子文件 | ✅ |
| @dir1 | 全部两个文件夹与子文件 | ❌,数字被忽略了 |
| @dir2 | 全部两个文件夹与子文件,但dir3优先级变高了 | ❌,同上 |
| @dir1/ | dir1 文件夹与子文件 | ✅ |
| @dir2/ | 空 | ❌,不能接受 |
| @test | 全部两个 test 子文件夹,以及相应子文件 | ✅ |
| @test/ | 空 | ❌,不能接受 |
| | | |

也就是说:**涉及到 slash(`/`)路径时,路径内不允许有括号等特殊字符,且必须从根路径开始**,这点尤其值得注意,所以目前的最佳实践是:
1. 直接输入不含特殊符号的目标文件名,然后在候选中勾选
2. 如果路径候选太多导致找不到,则直接使用 finder 确定目标路径,复制后粘贴
3. 如果路径中有空格,则使用引号包围

另外值得注意的是,区别于很多套壳应用(例如 cursor)、套壳插件(例如 cline)在引用文件时可能先读取并编码为:
{@file 之前的内容}
{读取的内容}{@file之后的内容}
ClaudeCode 作为一款 Agentic Tool 采用了更智能的 **按需读取** 策略,也即仅在后续需要使用文件内部内容时,才调用读取文件的工具进行读取,进行上下文理解,效率可能更高。

### 在 Claude Code 中使用图片
ClaudeCode支持图片发送,也支持基于图片的多模态理解,我们可以直接在ClaudeCode中粘贴图片进行发送,但在 Mac 上**快捷键是 `ctrl + V` 而非 `cmd + V`**。
尽管使用图片进行交流,在前端调试环节中,是更直观的一种方式,也方便基于 Playwright MCP (正如本教程中提及的)实现自动化调试,我还是推荐进阶用户能够掌握更多降维到文本的沟通技巧,以获取最大的兼容性。
例如有朋友在开发安卓自动化调试 Agent 的时候曾因为多张图片体积过大导致上下文窗口不够的问题,这种场景下就可以考虑基于某些模型并行地把图片转为文本嵌回上下文;再比如我们可以使用 `code-inspector` 插件精确确定前端某个组件的代码位置,然后让 ClaudeCode 精准修改,这比截图询问的效率与准确性要高得多得到。
>`code-inspector` 项目出发点是允许点击前端某组件自动跳转到源代码,我们会二开发布一个 code-inspector-for-ai 以支持更好的 Vibe Coding,敬请期待。
### 在 Claude Code 中使用 MCP
本期教学中,Elie老师只教大家安装了Playwright的MCP,命令如下:
```bash
claude mcp add playwright npx @playwright/mcp@latest
我们后续会有更多MCP相关的介绍,国内也有不少大佬写了MCP相关的科普,部分罗列如下,感兴趣都可以看看:

在本次教程中,Elie老师使用了多次 /clear,以清理上下文以实现新的需求,这个是很推荐的做法。
但个人实测中,我更喜欢用 /compact 以压缩(而非清理)上下文,以让 ClaudeCode 记住一些关键的经验。
比如视频中,Elie 老师明明已经说过一次不要自主运行服务器,第二次实现新需求时AI却忘了,就是因为Elie老师用了 /clear,但如果用 /compact就大概率不会有这个问题。
我们手工川、Vibe Genius社区的小伙伴们其实一直都在关注 /compact 这个指令的适用性与性能问题,后续我们会有更加详细的汇总同步,今天仅做抛砖引玉。
Context Engineering(上下文管理) 是当下大模型研究与应用的热点,我们需要多尝试、多对比、多总结,才能逐步提高自己的实战水平。

0:02 Now that you have an understanding
0:03 of the chatbot codebase, let's add features to the UI
0:06 and implement a new tool for the chatbot.
0:09 Now that we've gotten up to speed on this codebase,
0:12 let's talk a little bit about
0:14 some features we might want to add.
0:16 We saw before, in this application,
0:18 when we ask for an outline of a course,
0:21 we get some really detailed information
0:23 and we even see some of the sources that are referenced.
0:27 At the same time, when we see
0:29 these sources that are referenced, it would be really nice
0:32 to be able to click on these as links and go to
0:35 the source of truth.
0:37 So we want to build an interface
0:39 where the front end and back end
0:41 are correctly rendering links to show where
0:44 this data is coming from
0:46 and not just some text.
0:48 So let's hop over to Claude and talk
0:50 a little bit about how to get started.
0:52 What we're going to do here instead of
0:54 just asking Claude to implement the feature necessary,
0:57 we're going to make use of two important pieces.
1:00 The first one is referencing the correct file,
1:03 and the second is using plan mode.
... (省略 544 行) ...
12:33 Before it starts taking this action,
12:35 it's going to ask me for approval for these particular tools.
12:39 We'll see that it will visit
12:40 that page, take a screenshot and do do what's necessary.
12:44 Let's follow that and not ask for
12:46 permission each time to use this particular tool.
12:49 We can see here that the browser has opened a
12:52 new tab programmatically to our page to take a screenshot.
12:56 We'll ask Claude Code to take that screenshot
12:58 and analyze what it sees.
13:01 Here it can see the exact issue that's happening and instead of
13:05 us manually having to take the
13:07 screenshots necessary, it can programmatically fix itself.
13:09 We could have a more specific prompt as well, that keeps asking
13:13 Claude Code to make those changes necessary.
13:15 Since I don't have auto accept on, I can see the change
13:18 that's being made in VS Code.
13:20 And right out of the box, I don't
13:22 see a border and background with this
13:23 new change. That looks good to me.
13:25 Let's make those changes and continue making other changes.
13:28 I can see left align looking good.
13:31 and any other changes that need to be made here.
13:34 It's going to take another screenshot to
13:36 verify that the changes it's made look correct.
13:38 that it has the right icon prefixes used.
13:41 match other sections. With that in
13:43 mind, let's go see how he did.
13:45 I'm going to refresh the page. and it's looking good.
13:48 It's got an extra plus here. So why don't we go ahead
13:50 and ask it to take that
13:52 out. But it's left aligned and it's
13:53 using the icon that we like before.
13:56 So let's go ahead and fix this up and say,
13:59 there are now two plus icons, remove the
14:01 one closer to the text "+ New Chat"
14:04 We can see here there's already a plus in the HTML content,
14:07 so we'll remove that and let's see
14:09 what's done here. So instead of adding
14:11 that extra plus, we can see here what's being done.
14:13 If we need another snapshot, we
14:15 can visit and take a snapshot necessary.
14:18 As we can see here, Claude Code
14:20 saw there was not an open tab, so it fixed itself,
14:23 opened it up again and took the necessary screenshot.
14:27 Let's see what that looks like now. Much better.
14:30 As you can imagine, building complex interfaces
14:33 using tools like MCP playwright
14:36 makes building, designing and testing a breeze. We've made some really
14:40 nice front end changes. Let's now go and visit the back end.
14:43 Like we did before, we're going to start
14:46 fresh and instead of building off of this
14:48 conversation, we're going to start with a new one.
14:50 So let's clear the conversation history and start again.
14:54 This time, we want to build some features on the back end.
14:58 So let's put in a prompt, talk
14:59 about what's going to be done here.
15:01 I need to add another tool
15:03 that allows me to visit a particular course
15:07 and for each of those courses, see the
15:09 lesson number and the lesson title and description about that as well.
15:14 Right now, the data that I get
15:16 when I take a look at a course
15:18 is relatively high level. Let's see what I mean.
15:21 What we're going to ask Claude Code to do
15:23 here is to make a change to our search_tools.py file.
15:27 Let's take a look at that. And
15:28 in this file, we can see right now
15:30 that we just have one tool for searching
15:34 content and getting details about that particular course. This second tool
15:39 is going to allow us to get more descriptive information
15:43 for each of the lessons in these courses.
15:45 So let's see what Claude can do. As we've done previously,
15:49 let's make a plan and make
15:51 sure we're first okay with that plan
15:53 before we start making changes to individual files.
15:56 Claude Code can see the current
15:57 architecture, had to implement the outline tool,
16:00 and since we have that CLAUDE.md
16:02 previously, it's going to more quickly be able
16:04 to understand what needs to be done.
16:07 We can take a look at what needs to be implemented,
16:09 we can make sure that we're doing
16:11 the right things in the right files.
16:12 We can see that once we create this tool,
16:15 we update the system prompt to make
16:17 sure that we get that additional data,
16:19 and then we register that tool in our RAG system.
16:22 As always, if there's anything we want to
16:24 change or suggest, we can do that now.
16:27 But let's see what Claude Code can do for us.
16:29 If this works as expected,
16:31 we should be able to ask questions about a
16:34 course and get much more detail for those particular
16:37 lessons in the course.
16:39 We can see here that not only are we
16:42 modifying the underlying Python code, but also the system prompt
16:44 and here we're registering that new tool that we've made.
16:48 Once we finished our to-do list,
16:50 we can head back to the browser
16:52 and see what things look like
16:54 and if this has been implemented correctly.
16:56 We'll see a nice summary of what's been made
16:58 and we can always change things at any point in time.
17:01 Back in the browser, let's go ahead and try asking
17:04 for some information about a course.
17:06 If this works as expected.
17:08 We should be able to get more detailed information
17:11 including a link for that particular course.

17:14 Here, we can see the names of the lessons
17:16 and if we would like, we can even build additional functionality
17:20 to get sources for each one of those.
17:22 In the next lesson, we'll talk about what happens
17:25 when things go wrong and how we can use
17:27 Claude Code to debug, to write tests,
17:29 and make sure that we feel confident in
17:32 the software that we're writing alongside Claude Code.
手工川自研了适用于 claude code 和 gemini cli 的 meta slash command,可以基于 meta slash command 自动生成新的 slash command,并基于 claude code 思考分级机制生成了一套claude code thinking command set,由于文件过长,留言可领取。
以下是使用办法:
- 把这些文件都放在 ~/.claude/commands/ 目录下
- 在任意目录下启动 claude code,输入
/generate-command 你想生成的某个命令要解决的问题与目标,回车后即可自动生成一个你想要的命令,语法无需你刚刚提及的“i want to create a slash command, this command is to ............the input is .... output is ..........”,你甚至直接可以说“the input is .... output is ..........”,它会做完其他全部事。完成之后,退出cc,重新启动,输入/就能找到新的生成的命令了 - 在你正在开发的项目目录下,启动cc,输入
/think或者/think-hard或者/think-harder或者/think-ultra,接你的需求,就能强迫cc展开对应深度的思考 - toml 格式的command是用于gemini cli的,本 generate-command.toml 是基于适用于 claude code 的 generate-command.md 的 gemini cli 的变体版本,你可以基于 generate-command.toml 构建属于你自己的 gemini cli commands,但四级思考模式似乎是claude code专属的,我个人暂未基于gemini实现适用于gemini的四级思考模式
### 05.md
```markdown
欢迎来到手工川的《[吴恩达 x Anthropic:Claude Code 教程 · 第五期](https://learn.deeplearning.ai/courses/claude-code-a-highly-agentic-coding-assistant/lesson/33kzc/testing,-error-debugging-and-code-refactoring)》学习笔记。
在前几期的学习中,我们已经掌握了如何利用 Claude Code 理解代码库、添加新功能。但那些都还停留在“实现需求”的层面。真正的软件工程,远不止于此。一个健壮的系统,离不开完善的测试、优雅的重构和对错误的系统性调试。
今天,我们将深入一个在我看来是本系列课程至今为止 **最为震撼** 的环节。我们将不再把 Claude Code 仅仅看作一个代码生成器,而是将其提升到一个 **系统分析师** 和 **架构师** 的高度,去解决一个潜藏在项目中的 Bug,并完成一次极具挑战性的后端重构。
### 本期要点 (Key Insights)
1. **思维范式转变**:从“让 AI 修复 Bug”到“让 AI 编写测试来定位并修复 Bug”,我们将实践真正的 **测试驱动调试 (Test-Driven Debugging)**。
2. **高级指令工程**:学习如何通过 `think a lot` 和 `plan mode` 等指令,引导 AI 进行更深层次的、结构化的思考与规划。
3. **并行智能体头脑风暴**:见证 Claude Code 最强大的功能之一——通过一条指令 **派生出两个并行的子智能体 (Subagents)**,对同一个重构任务进行“头脑风暴”,并提出不同方案供我们选择。
4. **构建健壮性**:理解为什么先写测试、再做重构是保证系统稳定性的基石,以及如何让 AI 在整个过程中贯彻这一思想。
### 手工川笔记要点
我们之前的笔记里提及了 [claude code 官方最佳实践的几种范式](https://www.anthropic.com/engineering/claude-code-best-practices),其中前几节课里 Elie 老师主要采用了第一种 **Explore, plan, code, commit**,这在初始化项目、新增一个功能时非常有效。
今天是另一个开发中非常常见的场景:**调试(Debug) 与 重构(Refactor)**。
在 Debug 场景,尽管我们可以像上堂课一样手动截图(甚至用 Playwright 自动截图)发给 cc 让它去猜测原因并修复(**范式3:Write code, screenshot result, iterate**),但这种办法显然不是万全之策(就像治病越早越好,所以扁鹊医术评价可能要高于华佗一样),而且往往让大模型改的云里雾里。
Elie 老师希望我们能更多地掌握**测试驱动(TDD:Test Driven Development)** 的办法(**范式2:Write tests, commit; code, iterate, commit**)。
此外,Elie 老师一行 prompt 就能让 cc 并行多个 agent,然后左右互搏,也是非常值得学习的,我 highlight 于此,方便后续复查:”**Use two parallel subagents to brainstorm possible plans. Do not implement any code**“。
有意思的是,[前两天我们的 Vibe Seminar](https://mp.weixin.qq.com/s/jlDHxq4cCV-hn-tIS9I5fw)上 Weiyang 也分享了一套自己在研发的 MBTI Agent 系统,他可以让 16 个 MBTI 自动组队完成任务,非常有意思,大家感兴趣也可以了解一下,代码开源在:*https://github.com/weiyangzen/mbti-coding-agents* 。
## 场景复现:一个“静默”的 Bug
我们的 RAG 聊天机器人项目已经迭代了一段时间。现在,我们回到应用中,尝试提出一个之前能够正常工作的问题:“课程 5 涵盖了哪些内容?”
然而,前端返回了一个错误。

面对这个报错,大多数人的第一反应可能是复制错误信息,或者截张图,直接扔给 Claude,然后说:“嘿,帮我修好它。”
这当然是一种方法,但它治标不治本,并且充满了不确定性。我们不知道 AI 会如何修改代码,也无法保证这次修复不会引入新的问题。这是一种“黑盒式”的修复,对于追求卓越工程质量的开发者来说,是不可接受的。
所以,我决定采取一种更 methodical(系统化)的アプローチ。
## 测试驱动调试:为代码库建立“免疫系统”
我的核心思路是:**我们不仅要修复眼前的 Bug,更要为整个系统建立一个“免疫系统”——一套完善的自动化测试。** 这样,未来任何的修改导致了问题,我们都能在第一时间发现。
这个 Bug 可能源于多个文件:
- `AIGenerator`:处理与 Anthropic API 交互的地方,可能是 Prompt 出了问题。
- `rag_system.py`:作为 RAG 系统的“指挥官”,负责整个流程的编排。
- `search_tools`:定义了具体的搜索工具,这里也可能存在缺陷。
因此,我给 Claude Code 下达的指令,不是去“修复 Bug”,而是 **首先为这几个核心文件编写测试用例**。然后,通过运行这些测试,来定位并最终修复问题。
```ad-tip 测试驱动开发/调试 (TDD)
测试驱动开发(Test-Driven Development, TDD)是一种软件开发过程,它要求开发者在编写任何功能代码之前,首先编写一个会失败的自动化测试用例。然后,编写最少的代码来使这个测试通过,最后再对代码进行重构。
我们这里采用的是其变体——**测试驱动调试 (Test-Driven Debugging)**。当遇到一个 Bug 时,我们不是直接修改代码,而是先编写一个能够稳定复现这个 Bug 的测试。这个测试一开始必然是失败的。然后我们的目标就变成了让这个测试通过,这就意味着 Bug 被修复了。这种方法确保了 Bug 被真正理解和修复,并且防止了它在未来再次出现。
为了完成这个复杂的任务,我的 Prompt 经过了精心的设计。

我在这里使用了两个关键的“元指令”:
think a lot:这个指令会告诉 Claude Code,接下来的任务比较复杂,需要它分配更多的资源(token)来进行内部的“思考”过程。这使得它在制定计划时会更加周全和深入。plan mode:开启计划模式。这意味着 Claude Code 在真正开始修改文件之前,会先给出一个详细的行动计划。只有在我审查并批准这个计划之后,它才会开始执行。这给了我绝对的控制权,避免 AI “自由发挥”导致意外情况。
这个“先思考,再出计划,后执行”的流程,完美复刻了人类专家的工作模式,也是我们与 Agentic AI 高效协作的关键。
Claude Code 启动后,它的“思考”过程是完全透明的。我能看到它正在阅读哪些文件,以及它对问题的初步诊断:
- 初步诊断:它推测可能是配置问题、复杂的工具调用链中存在故障点,或是组件间的错误传递受限。
- 计划制定:
- 创建一个
tests/目录。 - 使用
pytest框架编写针对ai_generator.py,rag_system.py和search_tools.py的单元测试和集成测试。 - 为了隔离测试环境,它计划使用
mock来模拟ChromaDB等外部依赖。 - 安装必要的测试依赖(如
pytest)。 - 运行测试。
- 根据测试结果分析并修复 Bug。
- 创建一个
我批准了这个计划。接下来,Claude Code 开始了它的工作。

它首先创建了测试目录和文件,然后提示我安装 pytest。
**Pytest** 是一个成熟且功能强大的 Python 测试框架。它使得编写小型、可读的测试变得简单,并且可以扩展以支持复杂的函数式测试。
**Mocking**(模拟)是测试中的一个核心概念。当我们的测试对象依赖于其他复杂的组件(如数据库、网络API)时,我们不希望在测试中真实地去调用它们,因为这会让测试变慢、不稳定且难以设置。Mocking 允许我们用一个“假的”对象(Mock Object)来替代这些真实依赖。这个假对象完全在我们的控制之下,我们可以指定它在被调用时返回什么值,从而精确地测试我们的代码逻辑,而不用关心其依赖项的内部工作。
测试代码很快生成完毕。当我看到生成的测试文件时,我确信这套流程是正确的。代码结构清晰,使用了 pytest 的 fixtures(测试固件)来准备测试数据和 Mock 对象,这完全是专业级的测试代码。
接下来,Claude Code 运行了它自己编写的测试。果不其然,测试失败了。
根据失败的测试日志,它迅速定位到了问题的根源:在执行向量搜索时,返回结果的最大数量 MAX_RESULTS 被错误地设置为了 0。这是一个非常隐蔽的配置错误,如果靠人工去排查,可能需要花费不少时间。
它立即修改了配置,然后再次运行了所有测试。这一次,全部通过。
最后,它给出了一个全面的总结,报告了它发现的问题、进行的修复,以及它为项目新增的测试基础设施。
我回到浏览器,刷新页面,重新提出了那个问题。

这一次,我们得到了正确、详细的回答。Bug 被修复了。但更重要的是,我们的代码库现在拥有了一套自动化测试,成为了一个更健壮、更可靠的系统。
解决了 Bug,我准备迎接一个更大的挑战:代码重构。
我发现 ai_generator.py 中的一个设计缺陷:系统被硬编码为 每次用户查询最多只能进行一次工具调用(Tool Call)。
这意味着,对于简单问题,比如“课程 X 的大纲是什么?”,系统可以正常工作。但对于复杂问题,比如“对比课程 X 的第 4 课和课程 Y 的第 2 课,找出它们共同讨论的主题”,系统就无能为力了。因为要回答这个问题,至少需要两次工具调用:
- 获取课程 X 的大纲。
- 获取课程 Y 的大纲。
当前的架构无法支持这种多轮、连续的工具调用。我需要重构它。
这次的重构比修复 Bug 要复杂得多。它涉及到修改核心的业务逻辑,可能会有多种实现方案,每种方案都有其优缺点。我该选择哪一种?
此时,我决定使用 Claude Code 的一个堪称“杀手级”的功能。我没有直接告诉它“用方案 A”或“用方案 B”,因为连我自己也不是 100% 确定哪个方案最好。
于是,我编写了一个非常详细的 Prompt,保存在一个 backend-tool-refactor.md 文件中。这个 Prompt 的核心思想是:我不给你最终方案,我只给你目标和约束,然后你派生出两个并行的子智能体,去分别探索不同的实现路径,然后把方案拿给我来决策。
让我们来仔细剖析这个 Prompt 的精华部分:

Refactor @backend/ai_generator-py to support sequential tool calling where Claude can make up to 2 tool calls in separate API rounds.
# 1. 清晰定义现状
Current behavior:
- Claude makes 1 tool call → tools are removed from API params → final response
- If Claude wants another tool call after seeing results, it can't (gets empty response)
# 2. 清晰定义目标
Desired behavior:
- Each tool call should be a separate API request where Claude can reason about previous results
- Support for complex queries requiring multiple searches...
# 3. 提供具体示例
Example flow:
1. User: "Search for a course that discusses the same topic as lesson 4 of course X"
2. Claude: get course outline for course X - gets title of lesson 4
3. Claude: uses the title to search for a course that discusses the same topic → returns course information
4. Claude: provides complete answer
# 4. 给出明确的技术约束
Requirements:
- Maximum 2 sequential rounds per user query
- Terminate when: (a) 2 rounds completed, (b) Claude's response has no tool_use blocks, or (c) tool call fails
- ...
# 5. 提出元指令:派出子智能体
Use two parallel subagents to brainstorm possible plans. Do not implement any code.最后一句 “Use two parallel subagents to brainstorm possible plans. Do not implement any code.” 是整个任务的灵魂。我命令它扮演一个“技术经理”的角色,分派任务给两个“下属”(子智能体),让它们去进行方案调研。
当我执行这个 Prompt 后,终端里的景象让我叹为观止。

Claude Code 调用了一个名为 task 的内置工具,瞬间派生出两个并行的子进程。这两个子智能体开始同时工作,它们各自阅读代码库,分析需求,并独立地构思解决方案。
一个 **Agentic AI**(智能体 AI)系统,不仅仅是一个被动的问答或代码生成工具。它是一个具备自主性、能够设定目标、制定计划、使用工具并执行任务的系统。
**Subagents**(子智能体)的概念则将这一能力推向了新的高度。主智能体可以根据任务的需要,动态地创建和分派一个或多个专门的子智能体来处理子任务。这就像一个项目经理将一个大项目分解成多个小任务,然后分配给不同的团队成员去并行完成。这种“分而治之”的策略,极大地提升了 AI 解决复杂问题的能力和效率。
几分钟后,两个子智能体完成了它们的“头脑风暴”,并向我提交了各自的方案。

- 方案 A (Iterative Approach):一个迭代式的方法。它建议在现有
generate_response方法中加入一个循环,来处理多轮工具调用。这个方案改动较小,实现起来更安全,风险更低。 - 方案 B (Comprehensive Redesign):一个更全面的重构方案。它建议引入新的辅助方法来专门管理工具调用循环和状态,将多轮逻辑与核心生成逻辑解耦。这个方案从长远来看,代码结构更清晰,可维护性更好,但改动也更大。
现在,选择权回到了我的手上。Claude Code 完美地扮演了技术顾问的角色,它分析了两种路径,列出了利弊,等待我的决策。这种人机协作的模式,我认为是未来软件开发的终极形态。
我评估后,认为方案 A 作为当前阶段的实现更为稳妥。于是我回复:“Implement approach A”。
同时,我再次开启了 plan mode,确保在它动手之前,我能审查它的具体实施计划。
Claude Code 迅速给出了基于方案 A 的详细计划:
- 修改
generate_response方法签名,增加一个max_rounds参数。 - 更新系统 Prompt,告知模型它可以进行多轮工具调用。
- 在
handle_tool_execution中实现核心的循环逻辑。 - 最关键的一步:更新
test_ai_generator.py中的现有测试,并 增加一个新的测试用例,专门验证 sequential tool calling(顺序工具调用)的行为是否符合预期。
看到它主动提出要更新和增加测试,我感到非常欣慰。这表明它完全理解了软件工程的健壮性原则:任何重构都必须有测试来保驾护航。
我批准了计划。Claude Code 开始修改代码,并运行了新的测试。所有测试都顺利通过。

最后,我在前端进行了实际验证。我提出了一个真正需要多轮工具调用的问题:“有没有其他课程涵盖与 MCP 课程第 5 课相同的主题?”
为了回答这个问题,系统需要:
- 第一次工具调用:获取 MCP 课程的大纲,找到第 5 课的主题(例如,“构建 MCP 客户端”)。
- 第二次工具调用:用“构建 MCP 客户端”作为关键词,去搜索其他所有课程。
系统成功地执行了这个流程,并给出了答案:“看起来没有其他课程涵盖构建 MCP 客户端的主题。” 这个答案是准确的,更重要的是,它证明了我们的重构是成功的。
这一期的学习让我对 AI 辅助开发的未来充满了前所未有的期待。我们所见证的,已经远远超出了“自动补全”或“代码翻译”的范畴。
我们实践了两种软件工程领域至关重要的思想范式:
- 测试驱动的开发与调试:我们不再把测试看作是事后的负担,而是将其作为驱动开发、保证质量的“指挥棒”。通过让 AI 先写测试,我们确保了每一次修复和重构都是建立在坚实的基础之上的。
- 架构方案的探索与决策:通过开创性的“并行子智能体”功能,我们让 AI 参与到了软件设计中最具创造性的“头脑风暴”环节。AI 不再只是一个执行者,它成为了一个能够提供多种架构选项、分析利弊的“技术顾问”。
将这两者结合起来,就构成了一个高度可靠、高效的现代化软件开发工作流。我们作为开发者,角色也随之演变:我们不再是代码的“搬运工”,而是需求的“定义者”、AI 计划的“审批者”和最终结果的“验收者”。我们的工作重心,从具体的实现细节,提升到了更高层次的系统设计和质量把控上。
在下一期,我们将探讨如何通过 Git Worktrees 等工具,同时运行多个 Claude Code 会话来并行处理代码库的不同部分,进一步提升我们的开发效率。敬请期待!
### 01.md
```markdown
---
title: 吴恩达 x AnthropicClaude Code 终极教程 01
slug: x-anthropicclaude-code-01-1756023875040
source: https://mp.weixin.qq.com/s/wcAOpNHjngxyXdg2NV2kQg
captured_at: 2025-08-24T08:24:35.039Z
---
# 吴恩达 x Anthropic:Claude Code 终极教程 01
原创 南川同学 [手工川 - AI版](javascript:void(0);)
*2025年08月15日 17:34* *河北*
欢迎来到我们的新系列,由我们(手工川)为大家搬运并解读来自 DeepLearning.AI 与 Anthropic 官方合作的课程——**Claude Code: A Highly Agentic Coding Assistant**。

本系列旨在将这门顶尖课程的内容,以更符合中文读者习惯的方式呈现出来。我们将严格遵循专业、严谨的原则,对内容进行重组和精炼,并补充必要的图表以辅助理解。
今天,让我们从课程的开篇开始,由吴恩达和 Anthropic 的 Elie Schoppik 为我们揭开 **Claude Code** 的神秘面纱。

## 你将学到什么?
在本系列课程中,你将系统地掌握使用 **Claude Code** 的核心技能与最佳实践:
- **探索与开发:** 学会使用 **Claude Code** 来探索、开发、测试、重构和调试代码库。
- **能力扩展:** 通过 MCP 服务器(如 Playwright 和 Figma)来扩展 Claude Code 的核心能力。
- **项目实战:** 将 **Claude Code** 的最佳实践应用于三个真实项目中:
1. 探索和开发一个 RAG 聊天机器人的代码库。
2. 重构一个用于电子商务数据分析的 Jupyter notebook,并将其转化为一个交互式仪表盘。
3. 基于一个 Figma 设计稿,从零开始构建一个 Web 应用。
## 关于本课程
AI 编码助理正经历飞速的演进。从最初偶尔回答编程问题、提供代码补全,到如今能够自主生成和执行代码,工具的智能体化(Agentic)程度越来越高。
**Claude Code** 在这条路上迈出了关键一步,它不再是一个被动的工具,而是一个高度智能体的编程助理。它能够独立地进行规划、执行和代码优化,整个过程可持续数分钟甚至更久,且仅需少量的人工介入。更强大的是,你和你的团队现在可以同时运行多个 **Claude Code** 实例,并行处理代码库的不同部分。然而,要高效地协调这一切,需要一套尚未普及的最佳实践。
### 核心理念:提供清晰的上下文
本课程的核心,是教会你如何通过提供清晰的上下文,来最大化 **Claude Code** 的效率。关键技巧包括:
- **明确范围:** 精准指定相关文件。
- **定义目标:** 清晰描述所需的功能和特性。
- **善用生态:** 通过 MCP 服务器等工具连接外部能力。
### Claude Code 的架构与记忆机制
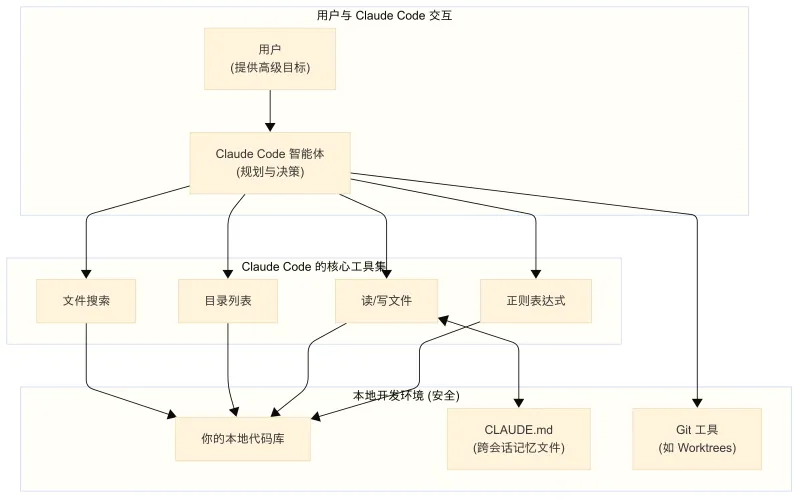
你可能会对 **Claude Code** 的底层架构感到惊讶——它的设计出奇的简洁。
它不依赖于将代码库进行复杂的语义嵌入或构建可搜索的索引。相反,它通过一小组核心工具(如文件搜索、目录列表、正则表达式匹配)来智能地阅读和理解你的代码。这种方法的优势在于,**你的代码库可以完全保留在本地**,确保了安全性。
**Claude Code** 的一个独特之处在于它会**主动地**在你的代码库中创建一个名为 `CLAUDE.md` 的文件。它像一个工作笔记,用来记录它对代码库的理解、关键信息和指导方针,从而实现跨会话的记忆。
## 适合人群
本课程非常适合任何希望探索 AI 编码助理以提升开发效率的开发者。无论你是正在构建应用、调试代码,还是探索不熟悉的代码库,你都将学到与 AI 协同工作的实用技能。
如果你熟悉 **Python** 和 **Git**,将会获得最佳的学习效果。
## 课程大纲
整个课程共包含 10 个核心视频课程,以及配套的测验与学习资料。
- **入门**
1. `课程介绍` (视频・4 分钟)
2. `什么是 Claude Code?` (视频・8 分钟)
- **核心功能与实践**
1. `环境设置与代码库理解` (视频・14 分钟)
2. `添加新功能` (视频・17 分钟)
3. `测试、错误调试与代码重构` (视频・12 分钟)
- **高级工作流**
1. `同时添加多个功能` (视频・11 分钟)
2. `Github 集成与 Hooks 探索` (视频・10 分钟)
- **项目实战**
1. `重构 Jupyter Notebook 并创建仪表盘` (视频・12 分钟)
2. `基于 Figma 设计稿创建 Web 应用` (视频・9 分钟)
- **总结**
1. `课程总结、测验与 Prompt 合集`
## 讲师介绍
**Elie Schoppik**
- **Anthropic 技术教育主管**
- 前 Firebase 开发者关系工程师,拥有丰富的开发者生态建设与技术布道经验。
* * *
### 手工川结语
以上就是吴恩达与 Anthropic 官方课程的第一期内容。它清晰地描绘了 **Claude Code** 作为一款高度智能体化编程助理的定位、核心优势以及我们即将通过本系列学习到的内容。
从下一期开始,我们将深入探讨 **Claude Code** 的具体工作机制,并开始第一个实战项目。请保持关注!
* * *
### 手工川
带你看一名极客眼中的 AI 世界。
* * *
参考资料:https://www.deeplearning.ai/short-courses/claude-code-a-highly-agentic-coding-assistant/?utm\_campaign=anthropicC3-launch&utm\_medium=headband&utm\_source=dlai-homepage#course-outline
此文档由 Context Packer 自动生成 项目路径: /Users/mark/my-docusaurus/my-website/my-documents/album/DeepLearning.ai-Courses-ClaudeCode/articles 生成时间: 2025年 8月24日 星期日 17时01分45秒 CST